坟墓里寂静无比,埋葬你的是你所有没说出口的话
[toc]
1.深度学习基础
线性模型
示例 y=b+wx1,损失是函数 L(b,w) ,计算 y 与 y^ 的差距e ,计算Loss: L=N1∑en.
e 有两种:
- 平均绝对误差(Mean Absolute Error,MAE):e=∣y^−y∣
- 均方误差(Mean Squared Error,MSE):e=(y^−y)2
有一些任务中 y 和 y^ 都是概率分布,这个时候可能会选择交叉熵(cross entropy),
根据不同的 L 画出的等高图:越大越红,越小越蓝,叫做误差表面(error surface)
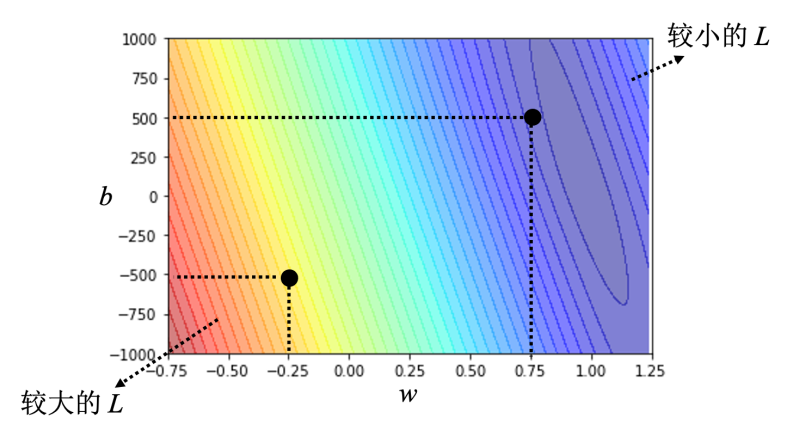
接下来是梯度下降(gradient descent)优化L:
w1←w0−η∂w∂Lw=w0,b=b0b1←b0−η∂b∂Lw=w0,b=b0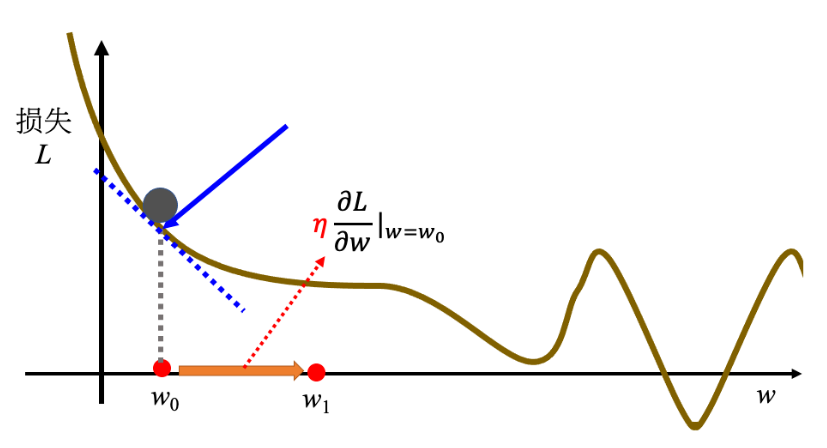
全局最小值(global minima),局部最小值(local minima)。
分段线性曲线
分段线性曲线(piecewise linear curve)可以看作是一个常数,再加上一堆Hard Sigmoid 函数。Hard Sigmoid 函数的特性是当输入的值,当 x 轴的值小于某一个阈值(某个定值)的时候,大于另外一个定值阈值的时候,中间有一个斜坡。
可以用 Sigmoid 函数来逼近 Hard Sigmoid:
y=c⋅1+e−(b+wx1)1
简化表示:
y=cσ(b+wx1)
表达整个函数时:
y=b+i∑ciσ(bi+wix1)wij 代表在第 i 个 Sigmoid 里面,乘给第 j 个特征的权重:
b1+w11x1+w12x2+w13x3那么括号中的为:
$$
r_1 = b_1 + w_{11} x_1 + w_{12} x_2 + w_{13} x_3
\\
r_2 = b_2 + w_{21} x_1 + w_{22} x_2 + w_{23} x_3
\\
r_3 = b_3 + w_{31} x_1 + w_{32} x_2 + w_{33} x_3
$$
用矩阵表示:
$$
\begin{bmatrix} r_1 \\ r_2 \\ r_3 \end{bmatrix} = \begin{bmatrix} b_1 \\ b_2 \\ b_3 \end{bmatrix} + \begin{bmatrix} w_{11} & w_{12} & w_{13} \\ w_{21} & w_{22} & w_{23} \\ w_{31} & w_{32} & w_{33} \end{bmatrix} \begin{bmatrix} x_1 \\ x_2 \\ x_3 \end{bmatrix}
$$
y=b+cTσ(b+cTa)计算θ:
首先给定θ的值,即某一组 W, b, cT, b的值。记最小的θ为θ∗,计算每一个未知的参数对 L 的微分,得到向量 g :g=∇L(θ0),∇L代表梯度
$$
g = \begin{bmatrix}
\left. \frac{\partial L}{\partial \theta_1} \right|_{\theta=\theta_0} \\
\left. \frac{\partial L}{\partial \theta_2} \right|_{\theta=\theta_0} \\
\vdots \\
\end{bmatrix}
$$
$$
\begin{bmatrix}
\theta^1_1 \\
\theta^2_1 \\
\vdots
\end{bmatrix}
\leftarrow
\begin{bmatrix}
\theta^1_0 \\
\theta^2_0 \\
\vdots
\end{bmatrix}
-
\eta
\begin{bmatrix}
\left. \frac{\partial L}{\partial \theta_1} \right|_{\theta=\theta_0} \\
\left. \frac{\partial L}{\partial \theta_2} \right|_{\theta=\theta_0} \\
\vdots \\
\end{bmatrix}
$$
即:
θ1←θ0−ηg实际使用梯度下降的时候,会把 N 笔数据随机分成一个一个的批量(batch),把所有的批量都看过一次,称为一个回合(epoch)。
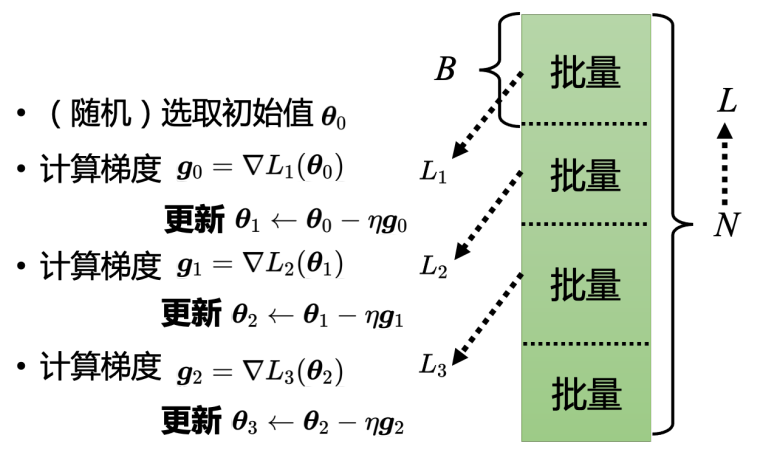
模型变形
Hard Sigmoid不一定非得是Soft Sigmoid,还可以是两个修正线性单元(Rectified Linear Unit,ReLU)的加总。
c⋅max(0,b+wx1)Sigmoid 或 ReLU 称为激活函数(activation function)。
y=b+i∑ciσ(bi+j∑wijxj)y=b+2i∑cimax(0,bi+j∑wijxj)
训练数据: {(x^1, y^1), (x^2, y^2), \ldots, (x^N, y^N)}
测试数据: x^{N+1}, x^{N+2}, \ldots, x^{N+M}
2.深度学习基础
局部极小值与鞍点
局部极小值与鞍点:
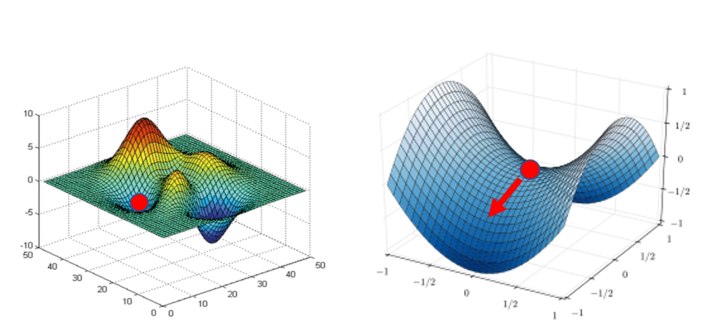
判断临界值种类的方法
θ′ 附近的 L(θ) 可近似为 :
L(θ)≈L(θ′)+(θ−θ′)Tg+21(θ−θ′)TH(θ−θ′)上式是泰勒级数近似,gi 是向量 g 的第 i 个元素,就是 L 关于 θ 的第 i 个元素的微分,即
gi=∂θi∂L(θ′)光看 g 还是没有办法完整地描述 L(θ),第三项跟海森矩阵(Hessian matrix)H 有关,H 里面是 L 的二次微分。它第 i 行,第 j 列的值 Hij 就是把 θ 的第 i 个元素对 L(θ′) 作微分,再把 θ 的第 j 个元素对 ∂θi∂L(θ′) 作微分后的结果,即
Hij=∂θi∂θj∂2L(θ′)可以根据21(θ−θ′)TH(θ−θ′)来判断在 θ′ 附近的误差表面(error surface)到底长什么样子。用向量 v 来表示 θ−θ′,(θ−θ′)TH(θ−θ′) 可改写为 vTHv。
有三种情况:
- 1
- 12
- 3
批量和动量
一般梯度下降:
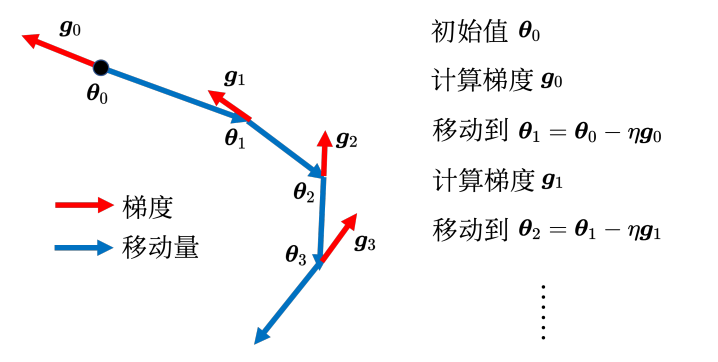
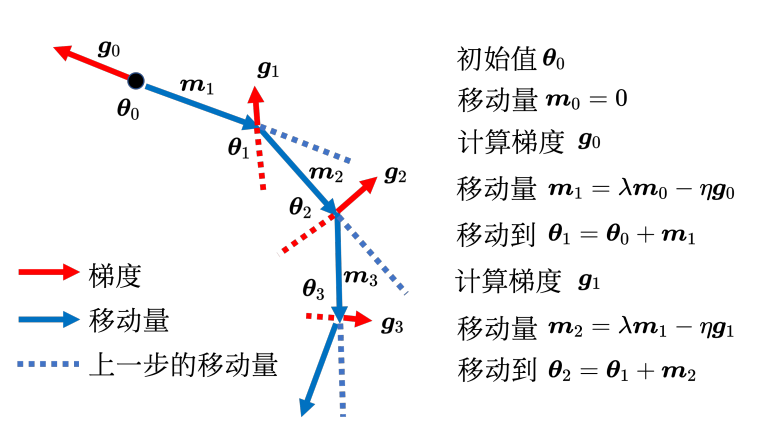
引入动量:
自适应学习率
在训练时,Loss会来回振荡:
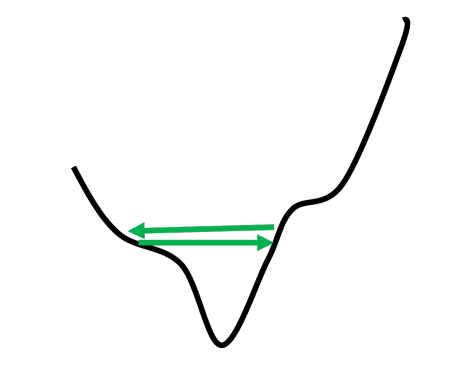
AdaGrad
AdaGrad(Adaptive Gradient)是典型的自适应学习率方法,其能够根据梯度大小自动调整学习率。
梯度下降更新某个参数 θti 的过程为
θt+1i←θti−ηgtiθti在第 t 个迭代的值减掉在第 t 个迭代参数 i 算出来的梯度。
gti=∂θi∂Lθ=θtgit 代表在第 t 个迭代,即 θ=θt 时,参数 θi 对损失 L 的微分,学习率是固定的。
现在要有一个随着参数定制化的学习率,即把原来学习率 η 变成 σtiη。
其中,上标 i 表示参数 σ 与参数 i 相关,不同的参数有不同的 σ;下标 t 表示参数 σ 与迭代 t 相关,不同的迭代也会有不同的 σ。
参数更新过程:
θ1i←θ0i−σ0iηg0i
其中 θ0i 是初始化参数。而 σ0i 的计算过程为
σ0i=(g0i)2=∣g0i∣
第二次更新参数过程为:
θ2i←θ1i−σ1iηg1i
其中 σ1i 是过去所有计算出来的梯度的平方的平均再开根号,即均方根
σ1i=21[(g0i)2+(g1i)2]第t+1 次更新参数的时候:
θt+1i←θti−σtiηgti
σti=t+11k=0∑t(gti)2RMSProp
同一个参数的同个方向,学习率也是需要动态调整的,于是就有了RMSprop(Root Mean Squared propagation)
第一步与Adarad一样:
σ0i=(g0i)2=∣g0i∣
第二步更新过程为
θ2i←θ1i−σ1iηg1iσ1i=α(σ0i)2+(1−α)(g1i)2之后亦是如此
Adam
最常用的优化的策略或者优化器(optimizer)是Adam(Adaptive moment estimation)
Adam 可以看作 RMSprop 加上动量
学习率优化
观察下图:
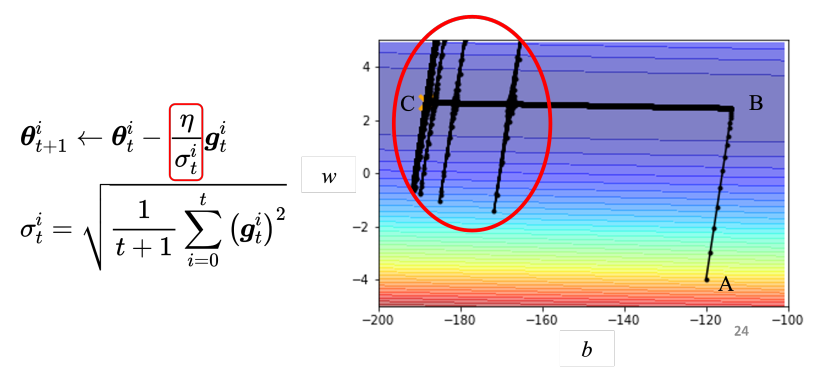
通过学习率调度(learning rate scheduling)可以解决这个问题。
θt+1i←θti−σtiηtgti
学习率调度中最常见的策略是学习率衰减(learning rate decay),也称为学习率退火(learning rate
annealing)。随着参数的不断更新,让 η 越来越小
除了学习率下降以外,还有另外一个经典的学习率调度的方式———预热。预热的方法是让学习率先变大后变小,至于变到多大、变大的速度、变小的速度是超参数。
如果读者想要学更多有关预热的东西可参考 Adam 的进阶版———RAdam
LIU L, JIANG H, HE P, et al. On the variance of the adaptive learning rate and beyond [J]. arXiv preprint arXiv:1908.03265, 2019.
分类