论文阅读 AlphaGo Moment for Model Architecture Discovery
论文阅读笔记:模型架构发现的AlphaGo时刻
摘要
尽管人工智能系统(AI systems)展现出指数级提升的能力,但人工智能研究(AI research)本身的速度却受限于人类的认知能力(human cognitive capacity),这造成了日益严重的开发瓶颈(development bottleneck)。本文介绍了 ASI-ARCH,这是人工智能研究领域(ASI4AI)中人工超级智能(Artificial Superintelligence for AI research)的首次演示,它在神经架构发现(neural architecture discovery)这一关键领域,通过使人工智能能够进行自身的架构创新(architectural innovation),打破了这一根本限制。
ASI-ARCH 超越了传统神经架构搜索(Neural Architecture Search, NAS),后者本质上局限于探索人类定义的空间(human-defined spaces),我们引入了从自动化优化(automated optimization)到自动化创新(automated innovation)的范式转变(paradigm shift)。ASI-ARCH 能够在架构发现这一挑战性领域进行端到端(end-to-end)科学研究,自主地提出新颖的架构概念(novel architectural concepts),将其实现为可执行代码(executable code),通过严格的实验(rigorous experimentation)以及过去人类和人工智能的经验进行训练和实证验证(empirically validating)其性能。
ASI-ARCH 进行了 1,773 次自主实验,耗时超过 20,000 GPU 小时,最终发现了 106 种创新的、最先进(state-of-the-art, SOTA)的线性注意力(linear attention)架构。就像 AlphaGo 的第 37 步棋揭示了人类玩家无法察觉的意想不到的战略洞察(strategic insights)一样,我们的人工智能发现的架构展现出新兴的设计原则(emergent design principles),这些原则系统地超越了人类设计的基线(human-designed baselines),并阐明了以前未知的架构创新途径(图 2)。
至关重要的是,我们建立了科学发现(scientific discovery)的第一个经验缩放定律(empirical scaling law)——证明架构突破(architectural breakthroughs)可以通过计算进行扩展(scaled computationally),将研究进展从人类受限(human-limited)的过程转变为计算可扩展(computation-scalable)的过程。我们提供了对促成这些突破的新兴设计模式(emergent design patterns)和自主研究能力(autonomous research capabilities)的全面分析,为自我加速(self-accelerating)的人工智能系统建立了蓝图(blueprint)。为了使人工智能驱动的研究民主化(democratize AI-driven research),我们开源了完整的框架、发现的架构和认知轨迹(cognitive traces)。
1. 引言
人工智能(AI)正以前所未有的深度和广度影响着人类社会,并被广泛认为是文明进步的关键驱动力(Russell and Norvig, 2010; Agrawal et al., 2018; Brynjolfsson and Mitchell, 2017)。然而,一个根本性的悖论(fundamental paradox)出现了:尽管人工智能系统展现出指数级提升的能力,但人工智能研究本身的速度却受限于人类的认知能力(The White House, 2023; Ahmed et al., 2022; Sevilla et al., 2022)。这种以人为中心(human-centric)的开发模式为人机智能的进步创造了日益严重的瓶颈,创新速度不再受限于计算能力,而是受限于人类的研究带宽(human research bandwidth)。这促使我们提出了一个变革性的愿景(transformative vision):用于人工智能研究的人工超级智能(ASI4AI)——能够自主进行科学研究并设计更强大的下一代模型的人工智能系统。
神经架构发现(Neural architecture discovery)是实现 ASI4AI 最具挑战性和影响力的前沿领域(frontier)。模型架构(Model architecture)是人工智能技术堆栈(AI technology stack)的基石,人工智能能力的每一次重大飞跃——从图像识别(image recognition)到自然语言理解(natural language understanding)——都伴随着相应的架构突破。从 CNNs (LeCun et al., 1995) 到 Transformers (Vaswani et al., 2017) 的演变,就例证了架构创新如何推动人工智能的根本性进步。当前研究的前沿,一个关键挑战是提高计算效率(computational efficiency)同时保持表达能力(expressive power)(DeepSeek-AI et al., 2024; MiniMax et al., 2025; Yuan et al., 2025)。为了将我们的探索建立在一个既具有根本重要性又活跃的研究领域,我们选择基于注意力(attention-based)的架构作为我们的试验台(testbed),利用其广泛的知识库(knowledge base)来探索人工智能真正的架构设计潜力(Katharopoulos et al., 2020; Choromanski et al., 2020; Tay et al., 2022; Wang et al., 2020)。
我们的工作超越了传统神经架构搜索(NAS),后者本质上局限于探索人类定义的空间,代表了从自动化优化到自动化创新的范式转变。虽然之前的 NAS 方法(Zoph and Le, 2016; Real et al., 2017; Elsken et al., 2019; Cheng et al., 2025)只能在预定的构建块(predetermined building blocks)上进行优化,并且计算成本高昂(prohibitive computational costs),充当复杂的选择算法(sophisticated selection algorithms)而非创造性代理(creative agents),但我们提出了 ASI-ARCH - 这是 ASI4AI 在神经架构发现领域的首次演示。ASI-ARCH 利用现代大型语言模型(LLMs)的先进推理(reasoning)和编码能力(coding capabilities)(Brown et al., 2020; OpenAI, 2023; Li et al., 2022),通过自主提出新颖的架构概念,将其实现为可执行代码,并通过严格的实验进行实证验证其性能(Chen et al., 2023; Zhang et al., 2024),从而超越了人类设计的搜索空间(human-designed search spaces)。
这代表了人工智能在神经架构设计领域首次展现出真正的科学超级智能(genuine scientific superintelligence)。就像 AlphaGo 的第 37 步棋揭示了人类玩家无法察觉的战略洞察一样,ASI-ARCH 发现的架构原则系统地超越了人类直觉(human intuition)。在进行了 1,773 次自主实验并耗费超过 20,000 GPU 小时后,ASI-ARCH 成功发现了 106 种新颖的、最先进的线性注意力架构。至关重要的是,我们建立了科学发现的第一个经验缩放定律——证明架构突破可以通过计算进行扩展,将研究进展从人类受限的过程转变为计算可扩展的过程,并为 ASI4AI 提供了具体的途径(concrete pathway)。
我们的主要贡献为自我加速的人工智能系统建立了蓝图,并推动了这一范式:
- ASI4AI 框架(ASI4AI Framework): 我们设计并构建了人工智能研究领域人工超级智能的首次演示,通过一个高度自主、以工具为中心(tool-centric)的多智能体系统(multi-agent system),使人工智能能够在神经架构发现领域独立进行整个科学研究过程——从假设生成(hypothesis generation)到实证验证。
- 新兴设计智能(Emergent Design Intelligence): 通过全面分析,我们识别了人工智能驱动的发现中出现的新颖设计模式,展示了超越人类设计范式(human design paradigms)并为注意力机制创新建立新原则的定性不同(qualitatively different)的架构智能。
- 发现的计算扩展(Computational Scaling of Discovery): 我们发现了 106 种新颖的、最先进的线性注意力架构,并建立了自动化科学突破的第一个缩放定律,证明研究进展可以随计算资源而非人类专业知识进行扩展。我们开源了完整的框架、发现的架构和认知轨迹,以使人工智能驱动的研究民主化。
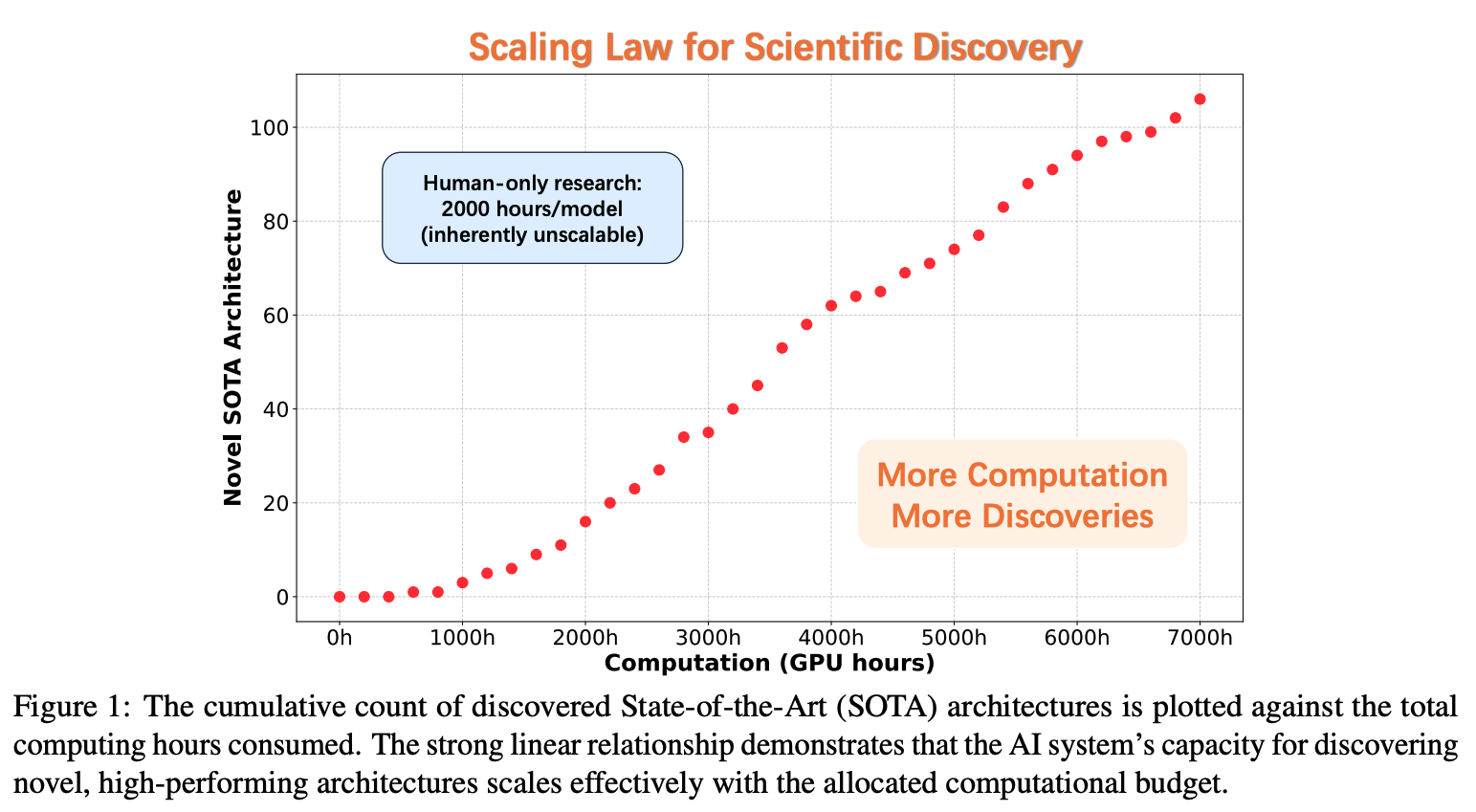 图 1:科学发现的缩放定律。图表显示了发现的最先进(SOTA)架构的累积数量与消耗的总计算小时数的关系。强大的线性关系表明,AI 系统发现新颖、高性能架构的能力与分配的计算预算有效地呈线性关系。
图 1:科学发现的缩放定律。图表显示了发现的最先进(SOTA)架构的累积数量与消耗的总计算小时数的关系。强大的线性关系表明,AI 系统发现新颖、高性能架构的能力与分配的计算预算有效地呈线性关系。
2. 相关工作
人工智能用于人工智能研究(AI For AI Research)
将人工智能应用于推进人工智能研究本身代表了一个引人注目的前沿领域(Kokotajlo et al., 2025),最好理解为科学过程中人工智能自主性(AI autonomy)不断提高的一个谱系(spectrum)。最初,人工智能的角色类似于一个复杂的助手,处理特定任务,例如在“副驾驶”(copilot)模型中生成代码,其中人类研究人员保留了对研究方向的完全控制。此后,这种协作已演变为人工智能作为“人工智能科学家”(AI scientist),能够独立生成新颖的假设并提出有前景的研究想法供人类考虑(Tshitoyan et al., 2019; Boiko et al., 2023)。最近,一些例子已经展示了人工智能在最少人为干预(minimal human intervention)的情况下完成整个研究周期的能力。例如,AlphaEvolve(Novikov et al., 2025; Cheng et al., 2025)等框架采用大型语言模型(LLMs)迭代地变异(mutate)和选择改进的程序变体(program variants),完成发现和改进的完整循环。同样,AlphaGeometry 在自主发现数学证明方面的成功展示了从问题陈述(problem statement)到解决方案(solution)的高度研究自主性(Trinh et al., 2024; Chervonyi et al., 2025)。随着人类在此协作循环中参与比例的降低,人工智能自我优化(self-optimization)的潜力变得越来越核心。这一概念以 Darwin-Gödel machines(Zhang et al., 2025)等自指系统(self-referential systems)为代表,这些系统旨在迭代修改自己的代码并实证验证这些更改,标志着向完全自我改进系统(fully self-improving systems)(Schmidhuber, 1997; Baum, 2004)的明确轨迹。
在此基础上,ASI-ARCH 将人工智能自进化(AI self-evolution)的原则应用于高度复杂的神经架构设计领域。这比之前的自我改进系统提出了更大的挑战,因为架构探索涉及一个明显更复杂的实验环境(experimental environment)和巨大的搜索空间(vast search space),成功无法得到保证。因此,我们的工作代表了在此更具挑战性和影响力的前沿领域推进人工智能自进化的重要尝试。
高效架构(Efficient Architecture)
Transformer 架构自推出以来一直主导着序列建模(sequence modeling),但其二次注意力复杂度(quadratic attention complexity)催生了对亚二次(sub-quadratic)替代方案的广泛研究,从而创建了一个日益复杂的设计空间(design space)(Vaswani et al., 2017)。在这些替代方案中,稀疏注意力(sparse attention)方法,如 Native Sparse Attention (NSA)(Yuan et al., 2025),采用分层稀疏策略(hierarchical sparse strategies),在保持模型能力的同时实现显著加速(substantial speedups)。除了稀疏注意力,还出现了三个主要具有线性时间复杂度(linear time complexity)的系列:线性注意力(Linear Attention),它使用线性化特征图(linearizing feature maps)(Katharopoulos et al., 2020; Choromanski et al., 2020; Qin et al., 2022);状态空间模型(State-Space Models, SSMs),如 Mamba,采用结构化状态转移矩阵(structured state transition matrices)(Gu and Dao, 2023; Dao and Gu, 2024);以及线性 RNNs(Linear RNNs),如 RWKV,具有矩阵值循环状态(matrix-valued recurrent states)(Peng et al., 2023; Qin et al., 2023, 2024b)。当前的趋势指向合成和混合(synthesis and hybridization),例如 Jamba 等架构交错(interleaving)不同的模型系列以利用各自的优势(Lieber et al., 2024; Qin et al., 2024a)。这种演变将格局从单一主导设计转变为一个巨大的组合空间(vast combinatorial space),其中最优架构高度依赖于特定任务和约束。虽然现有工作侧重于手动设计单个架构组件或系列,但这个过程通常是漫长的,需要人类专家数月的迭代努力才能产生一个最先进的架构。相比之下,ASI-ARCH 通过自动化多智能体协作(automated multi-agent collaboration)独特地解决了这个复杂设计空间的系统探索,从而能够发现超越传统系列边界的新颖架构。
3. 方法论
ASI-ARCH 框架作为一个用于自主架构发现的闭环系统(closed-loop system)运行,围绕一个具有三个核心角色的模块化框架(modular framework)构建。研究员模块(Researcher module)提出新颖的架构,工程师模块(Engineer module)通过在真实世界环境中执行它们来进行实证评估,分析师模块(Analyst module)对结果进行分析总结以获取新见解。所有实验数据和派生见解(derived insights)都系统地存档在一个中央数据库(central database)中,从而创建了一个驱动整个过程的持久内存(persistent memory)。
为了确保系统逐步生成更优的设计,我们实施了一种进化改进策略(evolutionary improvement strategy),使模型能够不断从经验中学习。这通过两种关键机制实现:首先,一个全面的适应度分数(comprehensive fitness score),它整体评估每个新架构,提供一个明确的优化目标(optimization target);其次,利用人类专家文献中提炼出的知识(distilled knowledge from human expert literature)(认知, cognition)和其自身过去实验的分析总结(analytical summaries of its own past experiments)(分析, analysis)来指导后续设计提案的能力。鉴于这种进化过程的资源密集性(resource-intensive nature),我们采用两阶段的探索-验证策略(two-stage exploration-then-verification strategy)。初始阶段涉及在小规模模型上进行广泛探索,以有效地识别大量有希望的候选模型。在最后阶段,这些候选模型被扩展到更大的模型进行严格验证(rigorous validation),以确认其最先进的性能。
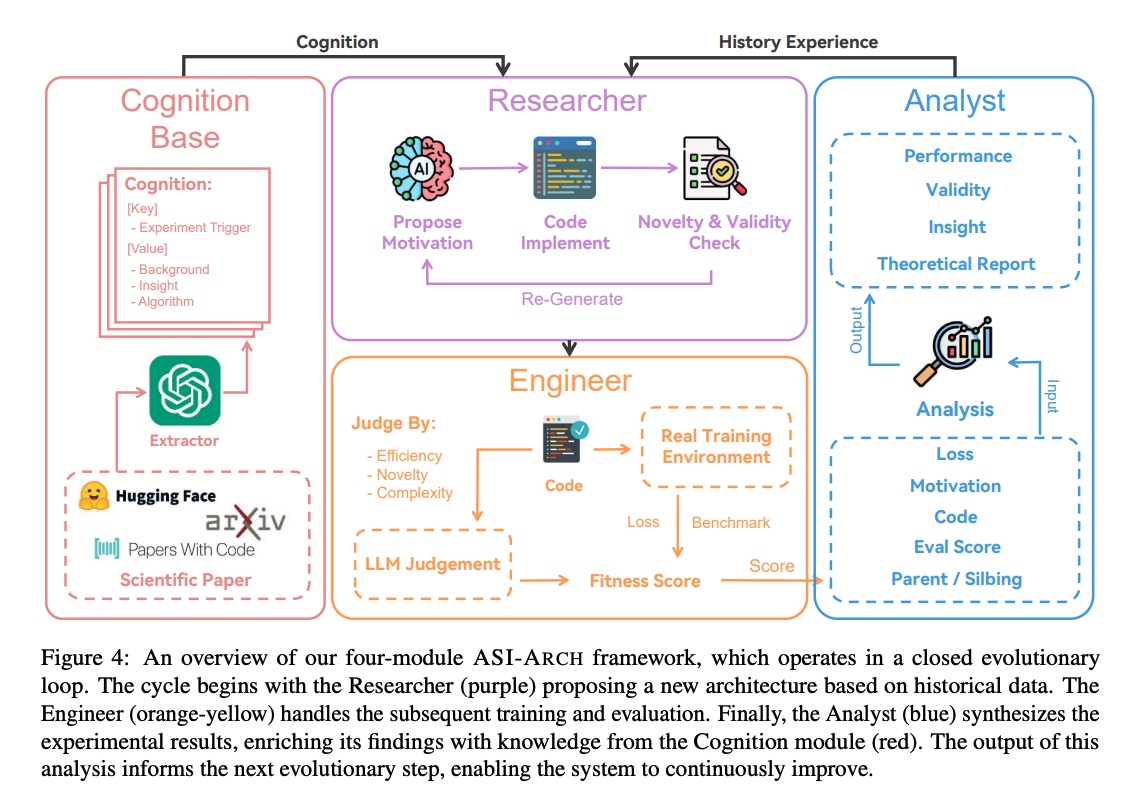
图 4:我们的四模块 ASI-ARCH 框架概述,它在一个封闭的进化循环中运行。循环从研究员(紫色)根据历史数据提出新架构开始。工程师(橙黄色)处理随后的训练和评估。最后,分析师(蓝色)综合实验结果,用认知模块(红色)的知识丰富其发现。此分析的输出指导下一步进化,使系统能够持续改进。
3.1 适应度函数(The Fitness Function)
ASI-ARCH 的模型架构演变模仿了生物进化,借鉴了自然选择(natural selection)的原则。在自然界中,适应度决定了生物体的生存和繁殖,类似地,我们定义了一个适应度函数,它控制着哪些架构在我们的进化过程中得以生存和繁殖。过去方法的一个关键缺陷是它们只依赖于损失(loss)和基准分数(benchmark scores)等定量指标(quantitative metrics)。这种狭隘的关注不可避免地导致奖励作弊(reward hacking)(Amodei et al., 2016),即系统学会最大化分数而没有产生真正优越的架构。我们通过引入对架构本身的定性评估(qualitative assessment)来扩展此定义。我们的复合适应度(composite fitness)结合了定量和定性维度,整体评估性能和设计质量:
在我们的框架中,客观性能评估(objective performance assessment)同时评估基准分数和相对于基线架构的损失性能。认识到科学突破通常源于渐进式进步(incremental advances),我们对性能差异应用了 Sigmoid 变换:。这种变换具有双重目的——放大微小但可能显著的改进,同时限制可能主导优化过程的极端值。对于架构质量评估,我们引入了一个单独的 LLM 作为专家评估器(expert evaluator),模仿人类专家如何判断架构优劣。该评估器检查多个维度:架构创新、结构复杂性(structural complexity)、实现正确性(implementation correctness)和收敛特性(convergence characteristics)。通过将这些定性评估与定量指标相结合,我们捕获了难以简单数值测量(simple numerical measurement)的架构质量。我们最终的复合适应度函数形式如下:
其中 和 表示相对于基线的 Sigmoid 变换性能改进, 提供归一化到 的主观质量评估(subjective quality assessment)。
3.2 研究员:提出新架构(Researcher: Propose New Architecture)
研究员模块(Researcher module)是我们系统的创造引擎(creative engine),人工智能在此模块中根据历史经验和人类专业知识独立提出新颖的模型架构。我们的设计旨在实现两个关键目标:确保高质量的架构创新,同时防止重复探索浪费计算资源。为了实现这些目标,我们实施了四个协同工作(work together)的关键机制:
种子选择(Seed Selection): ASI-ARCH 维护一个候选池(candidate pool),其中包含所有先前实验中得分最高的 50 个架构。对于每个进化步骤,我们使用两级采样方法(two-level sampling approach):从排名前 10 的模型中随机选择一个父架构(parent architecture)作为修改的基础,同时从排名 11-50 的模型中采样 4 个参考架构(reference architectures),以提供多样化的设计示例。这种两级选择确保了进化建立在已验证的成功之上,同时保持足够的随机性(randomness)以探索新方向。父架构直接被修改,而参考架构则作为成功设计模式的示例,本身不被更改。
模型设计(Model Design): 在向研究员提供历史数据以进行下一个进化周期之前,我们执行了一个关键的数据汇总步骤(data summarization step)。我们数据库中的每个架构都包含大量信息,包括其动机(motivation)、实现代码、实验结果和详细分析。为了管理上下文大小(context size),我们使用一个低温 LLM(low-temperature LLM)来为每个历史架构的自然语言部分生成简短的事实性摘要(brief, factual summaries)。至关重要的是,这些摘要是为每个进化周期动态生成(dynamically generated)的,并且不存储在数据库中。这种动态汇总过程(dynamic summarization process)固有地引入了相同历史数据随时间呈现方式的细微变化(subtle variations)。这不仅防止了研究员接收静态、重复的上下文(这可能会限制其输出的多样性),而且还积极鼓励更多样化的设计探索。最终的组合摘要(final combined summaries)为进化模型提供了可管理的上下文和不断更新的多样化见解,以指导下一次设计尝试。
程序实现(Program Implementation): 传统方法通常将架构设计与代码实现分开,为每个任务使用专门的模型。然而,这种分离会产生一个关键的信息鸿沟(information gap)——实现模型只看到高层动机,缺乏指导原始设计的丰富上下文。这通常会导致实现漂移(implementation drift),即最终代码与预期架构不同。ASI-ARCH 通过为这两个任务使用一个代理(single agent)来解决这个问题:首先在完全访问所有上下文的情况下提出架构动机,然后立即实现相应的代码,同时保持对设计推理(design reasoning)的完全感知。
新颖性和健全性检查(Novelty and Sanity Check): 为了确保每个提出的架构都是新颖的并且将正确实现,我们在接受训练之前实施了两阶段验证过程。第一阶段是相似性检查(similarity check),以防止冗余(redundancy)。当提出新架构时,我们首先提取其动机,并使用基于嵌入的搜索(embedding-based search)找到前 5 个最相似的历史动机。然后,一个专门的 LLM 评估新提案是真正的创新(genuine innovation)还是仅仅是现有工作的变体。第二阶段包括代码级健全性检查(code-level sanity checks),以防止基本的实现缺陷(fundamental implementation flaws),包括验证代码不超过 O(n2) 复杂度并确保正确实现掩码(mask)以防止信息泄露(information leakage)。如果提案未能通过新颖性或正确性检查,它将被拒绝,并将相关反馈返回给代理以提示重写(rewrite)。
3.3 工程师:训练和评估模型(Engineer: Train and Evaluate Models)
评估过程(evaluation process)为最终适应度分数提供数据,由两部分组成:在真实代码环境中的定量评估和由 LLM 作为评判(LLM-as-judge)的定性评分。
真实代码环境(Real Code Environment): 定量评估在交互式编码环境(interactive coding environment)中进行,代理必须利用一组定义的工具来启动训练、修改代码和检查错误日志。ASI-ARCH 的一个关键区别在于其强大的自我修正机制(robust self-revision mechanism)。与之前的工作(Cheng et al., 2025)形成鲜明对比的是,之前的工作通常使用抽象语法树(Abstract Syntax Tree, AST)解析等静态分析(static analysis),并简单地丢弃任何未能通过这些检查的架构,而 ASI-ARCH 要求代理修复自己的错误。当训练运行因实现错误而失败时,系统会自动捕获完整的错误日志(full error log)并将其返回给代理,然后代理的任务是分析此反馈并修改其先前生成的代码。这种迭代调试循环(iterative debugging loop)持续进行,直到训练成功,确保有希望的想法不会因简单的编码错误而过早地被丢弃。此外,为了保持高效率,自动化质量保证系统(automated quality assurance system)实时监控训练日志。这至关重要,因为一些功能设计可能效率极低,例如模型消耗的训练时间是同类模型的两到三倍。ASI-ARCH 会检测此类异常,以及异常低的损失指示的基本错误,并立即终止运行(terminates the run),将问题报告回代理进行修订。这种主动终止(proactive termination)可以防止在有缺陷的架构上浪费资源,并显著加速整个搜索过程。
LLM 作为评判评分(LLM-as-Judge Scoring): 在定量评估之后,我们启动一个基于 LLM 的评分模块(scoring module)以提供定性评估。此评分过程不仅考虑客观性能指标,还考虑架构复杂性、计算效率和所提出想法的新颖性,所有这些都与基线模型进行基准测试。为了确保一致性和可重复性(consistency and reproducibility),我们在提示(prompt)中提供了详细的教学大纲(detailed syllabus),并略微提高了模型的温度(model’s temperature),鼓励它为其分数生成更详细和细致的理由(nuanced justifications)。
3.4 分析师:挖掘实验见解(Analyzer: Mine Experimental Insights)
为了推动进化过程,ASI-ARCH 为代理提供了两种不同的知识来源,用于后续的每个设计步骤:源自累积人类专业知识的“认知”(cognition, derived from accumulated human expertise),以及从系统自身实验历史中动态生成的“分析”(analysis, generated dynamically from the system’s own experimental history)。
认知库(Cognition Base): 为了确保 ASI-ARCH 能够利用现有领域知识,我们构建了一个以认知为中心(cognition-centered)的知识库。我们从线性注意力领域选择了近 100 篇开创性论文(seminal papers),并使用专门的 LLM 从每篇论文中提取 1-3 个不同的认知。每个认知都是一个结构化条目(structured entry),由三个关键元素组成:适用场景(applicable scenario),描述原始论文旨在解决的具体问题;提出的算法(proposed algorithm),总结核心技术解决方案;以及历史背景(historical context),将论文置于其时代的研究趋势中。
为了保证此知识库的实用性,我们精心设计了用于提取 LLM 的提示。提示的结构专门设计用于确保提取的“实验触发器”(experiment trigger)与我们的分析师模块生成的“问题分析”(problem analyses)在语义上对齐(align semantically)。这种对齐对于有效检索(effective retrieval)至关重要。在分析的最后阶段,分析师总结了当前实验中观察到的具体缺点(specific shortcomings),此摘要用作基于嵌入检索的查询(query for embedding-based retrieval),对照我们知识库中的场景进行检索。然后,检索到的认知内容存储在我们的数据库中以供将来参考,为研究员模块提供了一种高度相关、信息密集且有针对性的解决方案查找方式。
上下文分析(Contextual Analysis): ASI-ARCH 通过一个由大型语言模型驱动的专用分析模块生成自己的见解。该代理被提供当前实验的完整信息集,包括所有性能指标、训练日志和基线模型的性能。此外,为了实现类似于消融研究(ablation study)的效果,我们还提供了系统发育树(phylogenetic tree)中当前架构的父节点(parent)和兄弟节点(sibling)的数据。基于这些节点共享显著结构相似性(significant structural similarities)的假设,我们期望代理通过比较这些密切相关架构之间的性能差异来推断单个模块的具体贡献。然后,将生成的分析存档以指导后续设计周期。
3.5 探索-验证策略(Exploration-then-Verification Strategy)
鉴于架构评估的资源密集性,我们采用两阶段探索-验证策略以保持可行性和效率。基本原则是,一个真正优越的架构应该在不同的设置中展现其优势。因此,在初始探索阶段,我们使用较小的模型和资源高效的协议(resource-efficient protocols)来快速识别大量有希望的候选模型,这些模型优于基线。在随后的验证阶段,只有这些有希望的候选模型被扩展到更大的参数大小,进行广泛训练和针对已建立的最先进基线的严格验证。这种两阶段方法使我们能够平衡广泛探索的需求与彻底、高保真验证(high-fidelity validation)的必要性。
4. 实验
4.1 实验设置(Experimental Setup)
适应度函数(Fitness Function): 在我们的实验中,我们使用 DeltaNet (Yang et al., 2024b) 作为基线。如第 3.1 节所述,我们的评分系统由三个组件组成。对于定量评分,由于线性注意力中的架构差异通常会产生较小的性能变化,我们只关注基线 10% 以内的差异,并通过 Sigmoid 函数将其映射以获得分数。此外,损失高于基线 10% 的架构被认为存在信息泄露(information leakage),并立即被丢弃。对于定性评分,我们建立了一个校准量表(calibrated scale),DeltaNet 为 5 分作为中点,Gated DeltaNet (Yang et al., 2024a) 为 10 分作为上限参考。LLM 评估器在此 1-10 量表上评估每个架构。
并行搜索架构和策略(Parallel Search Architecture and Policy): 为了加速发现,我们并行运行了许多搜索过程。这由一个基于云的数据库支持,该数据库存储所有历史实验结果,允许不同的代理通过 API 服务添加或请求数据并共享所有累积知识。为了有效管理这种并行探索同时鼓励多样性,我们实施了一个战略性候选池更新策略(strategic candidate pool update policy):
- 冷启动(Cold Start): 在实验开始时,ASI-ARCH 进行 200 次探索而不更新数据库。这个初始阶段鼓励模型广泛探索多样化的架构框架,而不是立即收敛到早期发现的变体。
- 批处理更新(Batched Updates): 冷启动期结束后,我们每 50 个新条目才更新候选池,而不是动态选择前 50 个。这种批处理方法确保所有代理在每个探索阶段都使用稳定的参考集,从而促进一致性,而初始延迟则促进了创造力。
面向效率的框架设置(Efficiency-Oriented Framework Settings): 如我们的方法论所述,我们的搜索过程分为两个具有不同配置的阶段:
- 探索阶段(Exploration Stage): 为了实现大规模探索,我们将模型大小限制在大约 20M 参数,并在 1B 令牌上进行训练。对于评估,我们每个基准只采样 500 个示例,以平衡评估质量和计算效率。
- 验证阶段(Verification Stage): 探索阶段最有希望的候选模型被推进到严格的验证阶段。在这里,我们将架构扩展到 400M 参数,并在 1B 令牌上训练它们以进行初始性能验证。然后,从该组中选择表现最好的模型进行最终的、更广泛的 15B 令牌数据集训练,以全面评估其与强大基线的性能。
4.2 主要结果(Main results)
为了平衡探索效率和验证准确性,我们采用了两阶段策略:首先在小型模型上进行初始探索,然后在大型模型上进行验证。在第一阶段,我们使用 20M 参数模型进行了 1,773 次探索,消耗了大约 10,000 GPU 小时。
表1:语言模型和零样本常识推理的性能比较
类型(Type)表示模型是人类设计还是人工智能发现。
| Model | Type | Wiki. ppl | LMB. ppl | LMB. acc↑ | PIQA acc | Hella. acc n↑ | Wino. acc↑ | ARC-e acc↑ | ARC-C acc_n↑ | SIQA acc↑ | BoolQ ace↑ | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mamba2 | (Human-designed) | 27.08 | 40.09 | 31.32 | 67.90 | 42.25 | 51.46 | 62.04 | 29.27 | 39.25 | 59.24 | 47.84 |
| Gated DeltaNet | (Human-designed) | 27.62 | 38.69 | 31.42 | 68.28 | 40.77 | 51.14 | 61.03 | 27.05 | 38.79 | 60.12 | 47.32 |
| DeltaNet | (Human-designed) | 27.41 | 42.08 | 30.41 | 67.63 | 40.82 | 50.83 | 61.07 | 29.27 | 40.02 | 52.23 | 46.54 |
| PathGate FusionNet | (AI-discovered) | 26.76 | 37.40 | 33.17 | 68.77 | 41.57 | 53.91 | 61.03 | 29.61 | 39.46 | 60.58 | 48.51 |
| ContentSharpRouter | (AI-discovered) | 26.80 | 36.58 | 32.72 | 67.79 | 40.78 | 53.12 | 61.07 | 30.20 | 40.79 | 60.28 | 48.34 |
| FusionGatedFIRNet | (AI-discovered) | 26.37 | 33.44 | 33.38 | 68.61 | 42.20 | 50.99 | 62.50 | 28.92 | 40.48 | 59.24 | 48.29 |
| HierGateNet | (AI-discovered) | 26.56 | 36.83 | 32.23 | 68.93 | 41.30 | 52.64 | 62.75 | 29.95 | 39.71 | 58.38 | 48.24 |
| AdaMultiPathGateNet | (AI-discovered) | 26.62 | 38.31 | 31.65 | 68.06 | 41.37 | 53.43 | 62.04 | 29.01 | 39.36 | 60.52 | 48.18 |
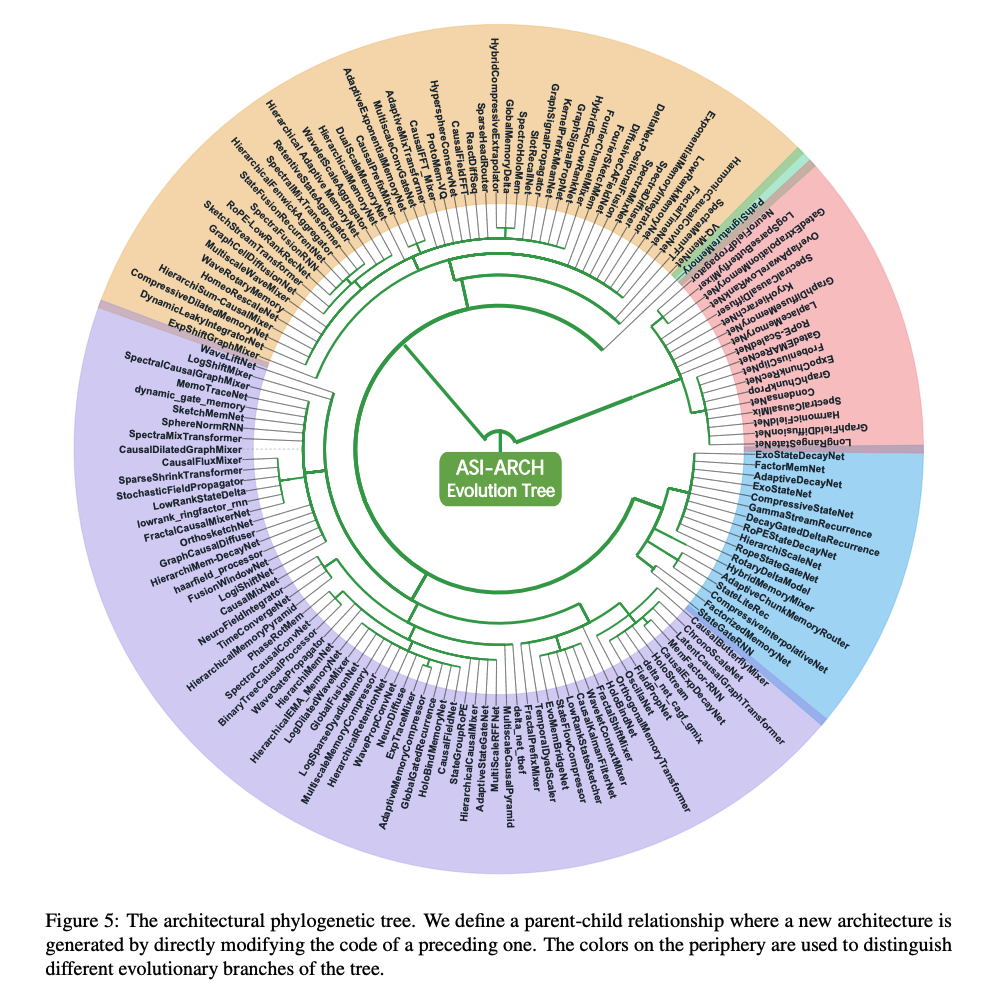
图 5 展示了第一阶段的部分系统发育树。从这些实验中,我们筛选出在相同参数规模下,在损失和基准指标上均优于 DeltaNet 的架构,产生了 1,350 个有希望的候选模型。在第二阶段,我们将这些候选模型扩展到 340M 参数,与 DeltaNet 的配置相匹配,并筛选掉复杂度或参数数量过多(excessive complexity or parameter counts)的架构。然后,我们训练了大约 400 个模型架构,在 1B 令牌上,消耗了 10,000 GPU 小时。其中,106 个架构取得了最先进的结果,所有这些架构都可以在我们的模型库网站(Model Gallery website)上公开获取,供社区参考。为了最终验证,我们选择了 5 个表现最好的架构,并在 340M 参数设置下,在 15B 令牌上训练它们。这些模型在相同的实验设置下与 DeltaNet、Gated DeltaNet 和 Mamba2 进行了比较。如表 1 所示,我们的模型在各种基准测试中几乎都优于所有基线。为最终验证选择的五个架构如下所述,每个都代表了改进 DeltaNet 基线的不同策略:
- 分层路径感知门控(Hierarchical Path-Aware Gating, PathGateFusionNet): 该架构引入了一个分层两阶段路由器(hierarchical, two-stage router),以解决局部和全局推理(local and global reasoning)之间的权衡。第一阶段在直接复制路径(direct copy path)和上下文池(contextual pool)之间分配预算,而第二阶段将该上下文预算分配到短程(short-range)、长程(long-range)和 Delta 规则路径。它通过一个小的、始终开启的残差连接(always-on residual connection)确保稳定的梯度流(stable gradient flow),并添加了头部特定(head-specific)的输出门以进行细粒度的局部控制(fine-grained local control)。
- 内容感知锐度门控(Content-Aware Sharpness Gating, ContentSharpRouter): 该模型解决了创建既内容感知又能做出决定性(锐利, sharp)路由决策的门控的挑战。它融合了两个关键思想:一个使用令牌嵌入(token embeddings)和路径统计信息(path statistics)来指导其决策的内容感知门控,以及一个可学习的、每个头部温度参数(learnable, per-head temperature parameter),允许模型动态控制路由 softmax 的锐度,防止过早的门控崩溃(premature gate collapse)。
- 带有保留的并行 Sigmoid 融合(Parallel Sigmoid Fusion with Retention, FusionGatedFIRNet): 该架构从根本上改变了门控机制,以打破 softmax 施加的“零和”(zero-sum)权衡。它用每个路径的并行、独立的 Sigmoid 门替换了单个 softmax 路由器。这使得模型能够同时激活局部和全局路径。它还通过一个可学习的、每个头部保留参数(learnable, per-head retention parameter)增强了 Delta 规则,赋予其可控的记忆范围(controllable memory horizon)。
- 带有动态下限的分层门控(Hierarchical Gating with Dynamic Floors, HierGateNet): 该模型采用两阶段分层门控来分离宏观(macro, local vs. global)和细粒度路由决策。其关键创新是为每个路径和头部使用动态、可学习的下限(dynamic, learnable floors)。这种机制确保没有关键路径(特别是用于长程推理的 Delta 路径)会完全崩溃,根据上下文调整其最小分配。
- 自适应多路径门控(Adaptive Multi-Path Gating, AdaMultiPathGateNet): 该设计侧重于在最细粒度上提供最大控制。它实现了一个统一的 BalancedSparseGate,结合了全局、每个头部和每个令牌的 logits,允许在令牌级别控制每个路径。为了防止门控崩溃,它结合使用了一个小的 epsilon-下限(epsilon-floor)和一个持久的、始终开启的熵惩罚(entropy penalty),确保路径多样性而无需复杂的训练计划。
5. 分析
ASI-ARCH 中架构的演变由一个候选池驱动,该候选池在每生成 50 个新架构后更新。由于每个架构变异步骤都只引用该池中的数据,因此我们根据生成顺序顺序分析搜索过程,以 50 个架构为基本分析单元。为了方便我们调查高性能模型的区别,我们将前 106 个架构统称为“模型库”(model gallery)。
5.1 LLM 驱动架构搜索的有效性(Effectiveness of LLM-Driven Architecture Search)
为了证明我们 LLM 驱动的神经架构搜索系统的有效性,我们检查了搜索过程如何随时间演变。由于我们的系统仅从前 50 名候选池中选择父架构进行修改,因此该池的特性直接决定了搜索轨迹(search trajectory)和最终性能。因此,我们分析了与此候选池相关的两个关键指标集:(1)前 50 名候选模型的平均适应度分数的总体趋势及其三个组成部分的个体趋势:损失改进、基准改进和 LLM 评判分数;以及(2)这些相同候选模型的平均原始性能,特别是基准分数和损失值。这些指标共同提供了我们系统搜索动态(search dynamics)和持续优化过程的全面视图。
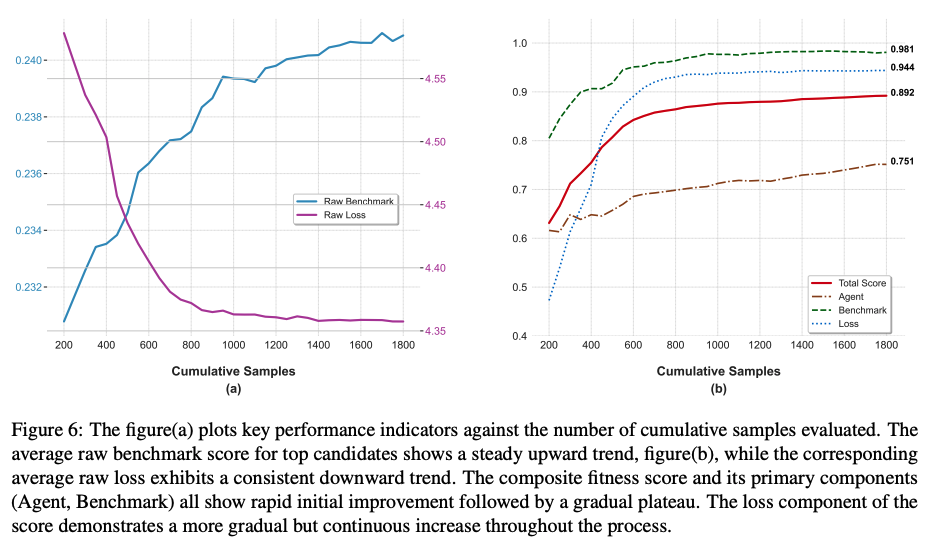
图 6:该图 (a) 绘制了关键性能指标与累积评估样本数量的关系。图 (b) 显示,顶级候选模型的平均原始基准分数呈稳定上升趋势,而相应的平均原始损失则呈持续下降趋势。复合适应度分数及其主要组成部分(Agent, Benchmark)均显示出快速的初始改进,随后逐渐趋于平稳。分数中的损失组成部分在整个过程中表现出更渐进但持续的增长。
对搜索动态的分析揭示了几个互补的模式。首先,前 50 名候选模型的平均适应度分数遵循典型的学习曲线(characteristic learning curve),初始阶段快速增长,随后逐渐稳定(图 6b)。早期阶段的分数增长主要由损失组件的优化驱动。随后的稳定化是我们的适应度函数设计的直接结果;由于 Sigmoid 变换,即使后期阶段的显著性能提升也会映射到较小的分数增长。这通过限制任何单一指标的分数贡献来防止奖励作弊,从而阻止过度优化。重要的是,尽管适应度分数增长按设计趋于平缓,但系统并未遇到性能瓶颈(performance bottleneck),这由原始基准和损失指标的持续稳定改进所证实。这种收敛证据(convergent evidence)证实,我们的 LLM 驱动搜索在整个搜索过程中有效地学会了生成更优的架构。
5.2 架构设计模式(Architectural Design Patterns)
为了理解 LLM 在搜索过程中对架构的偏好,这可以提供关于这些模型如何处理设计空间的见解,我们分析了复杂性趋势和组件偏好。
模型复杂性稳定性(Model Complexity Stability): 神经架构搜索中的一个基本问题是性能提升是否仅仅来自模型大小的增加。我们使用参数数量(parameter count)作为模型复杂度的代理(proxy)来检查这个问题。图 8 显示了迭代过程中参数数量的分布。数据显示,虽然早期迭代主要生成 400-600M 参数范围内的模型,但系统很快多样化以探索 600-800M 参数之间的模型。重要的是,在初始探索阶段之后,参数分布保持稳定,没有系统性增长。在整个搜索过程中,大多数架构始终落在 400-600M 范围内,没有出现模型越来越复杂的趋势。这种稳定性表明 ASI-ARCH 没有将复杂的组件堆叠(complex component stacking)作为一种简单的性能改进策略,即使没有明确的参数约束,也保持了架构的规范性(architectural discipline)。
架构组件偏好(Architectural Component Preferences): 为了理解 LLM 的底层设计策略,我们对其选择修改的架构组件进行了细粒度分析(fine-grained analysis)。我们使用一个单独的大型语言模型来解析系统生成的每个动机,识别每个步骤中哪些特定模型组件被修改。这个过程产生了大约 5,000 个组件实例(component instances),然后我们手动整理并将其分组为 40 个高级类别。然后,我们统计比较了这些类别在我们高性能模型库中的使用比例与其余模型中的使用比例。图 7 中可视化的比较分析揭示了我们 LLM 驱动设计过程的两个关键见解。首先,ASI-ARCH 明显偏好门控机制(gating mechanisms)和卷积(convolutions)等已建立的架构组件,而物理启发机制(physics-inspired mechanisms)等不常见的组件则很少出现,这可能反映了训练文献中的偏差(biases in the training literature)。其次,更具启发性的是,模型库在其组件使用中表现出明显不那么显著的长尾分布(long-tail distribution)。这表明,虽然系统探索了许多新颖的组件,但表现最好的模型收敛到一组经过验证且有效的核心技术。这反映了人类科学家典型的研究方法:通过主要在经过验证的技术基础上进行迭代和创新来获得最先进的结果,而不是为了新颖性而追求新颖性。
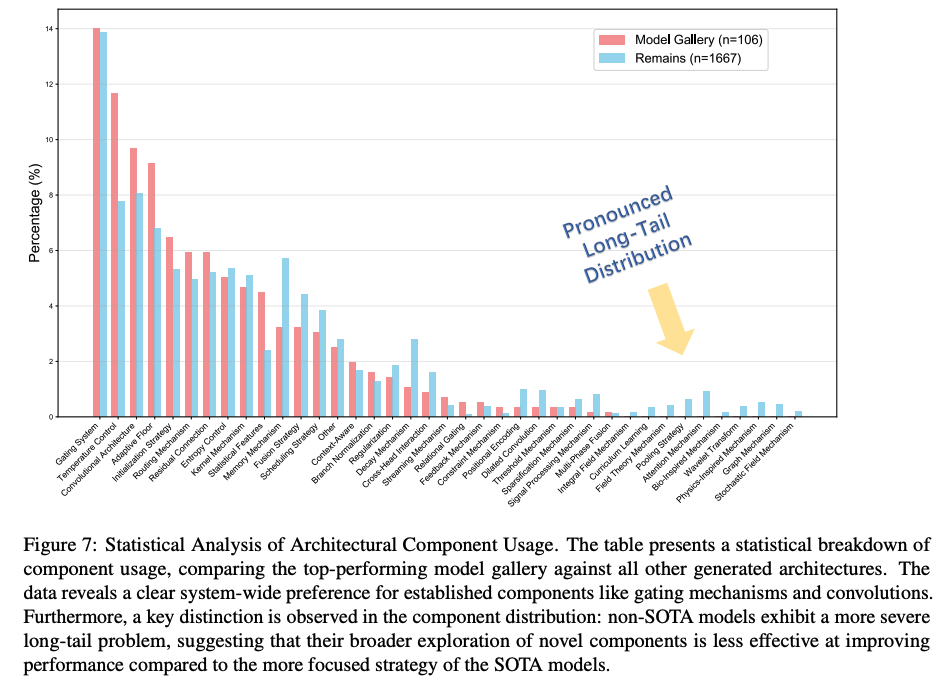
图 7:架构组件使用情况的统计分析。该表提供了组件使用情况的统计细分,比较了表现最佳的模型库与所有其他生成的架构。数据揭示了系统对门控机制和卷积等已建立组件的明确偏好。此外,在组件分布中观察到一个关键区别:非 SOTA 模型表现出更严重的“长尾问题”,这表明它们对新颖组件的更广泛探索在提高性能方面不如 SOTA 模型更集中的策略有效。
5.3 好的设计从何而来?(Where Do Good Designs Come From?)
为了指导未来更高效和自适应框架的开发,了解 ASI-ARCH 的哪些组件对模型架构设计产生最显著的影响至关重要。我们系统的设计过程受其输入限制:对于每个新架构,模型的上下文严格限于从候选池中提取的五个历史实验记录的动机、程序、实验结果、分析和认知部分。鉴于这种有限的上下文,我们可以假设任何新的设计灵感都必须来自三个渠道之一:从人类专家文献中提炼出的知识(我们称之为认知, cognition)、通过对其相关历史实验的分析和总结识别出的模式(分析, analysis),或模型本身生成的新想法(原创, original)。为了量化这三个渠道的贡献,我们设计了一个实验来追溯每个设计思想的来源(provenance of each design idea)。我们提示一个 LLM,充当公正的评估者(impartial evaluator),根据其最可能的来源对每个架构组件(如我们之前的动机分析中识别的)进行分类,将其分类为源自认知、分析或作为原创思想。
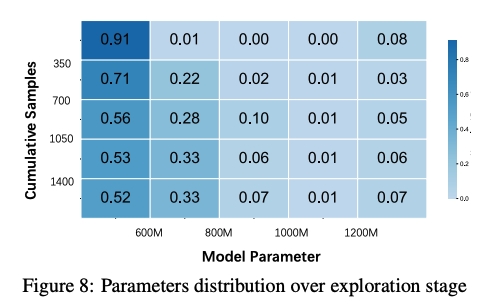
表 3 中显示的结果揭示了一个引人注目的双重模式(compelling two-fold pattern)。在所有生成的架构中,大多数设计思想源自认知阶段,表明对直接的先前示例存在基线依赖(baseline reliance)。然而,当我们专门关注模型库时,观察到显著的转变。对于这些表现最好的架构,归因于分析阶段的设计组件比例显著增加(increases markedly)。这一发现表明了与人类科学进步的关键相似之处:虽然能力可以建立在直接经验之上,但要实现真正的卓越需要更深层次、更抽象的理解。它证明,要使人工智能产生突破性结果,它不能仅仅重用过去的成功(依赖于认知)。相反,它必须参与探索、总结和发现的过程(依赖于分析),以合成新颖和卓越的解决方案。
表 3:管道组件对 SOTA 模型设计与其他模型设计影响的比较。数据显示,SOTA 架构的开发对经验分析的依赖程度更高。
| Category | Experience | Cognition | Originality |
|---|---|---|---|
| Model Gallery | 44.8% | 48.6% | 6.6% |
| Others | 37.7% | 51.9% | 10.4% |
| All | 38.2% | 51.7% | 10.1% |
讨论和未来工作(Discussion and Future Work)
我们的工作成功地展示了一个用于人工智能自我优化(AI self-optimization)的框架,其中自主代理可以迭代地发现和完善新颖的神经架构。本研究的主要重点是建立这种方法的可行性(viability of this methodology)——证明人工智能可以驾驭复杂的设空间以实现最先进的性能。我们的发现为未来的研究开辟了几个有前景的方向。
多架构初始化(Multi-Architecture Initialization): 我们目前的方法从一个单一的、强大的基线(DeltaNet)开始搜索。这是一个经过深思熟虑的方法论选择(deliberate methodological choice),它提供了一个明确的目标和稳定的基础来推动持续改进,这在探索此类框架的早期阶段至关重要。一个自然而令人兴奋的扩展将是同时用多样化的架构组合(diverse portfolio of architectures)来初始化该过程。这不仅会测试框架管理更复杂、多模态搜索(multi-modal search)的能力,还可能导致发现全新的架构家族。然而,这种尝试将需要计算资源和时间的显著增加。
组件级分析(Component-wise Analysis): 我们的实验验证了我们管道作为一个整体的有效性。由于每次设计迭代需要大量资源,我们没有进行细粒度的消融研究(fine-grained ablation study)来隔离框架内每个组件的贡献。未来工作的一个关键途径是从多个角度剖析管道(dissect the pipeline from multiple angles),以更好地理解其各个部分的相互作用和个体重要性,例如“认知”和“分析”模块。这将使框架能够进行更有针对性的优化(targeted optimization),可能带来更高的效率和创造力。
工程优化(Engineering Optimization): 本文的核心贡献在于人工智能用于人工智能框架本身的设计,重点是架构创新和性能。因此,我们没有将我们的工作扩展到包括为新发现的架构编写自定义加速内核(custom accelerated kernels)(例如,使用 Triton)的劳动密集型任务(labor-intensive task)。因此,没有提供它们的计算效率的直接比较。下一步的关键,特别是将这些设计从研究过渡到实践,将是关注这一工程方面。对这些模型的效率和延迟进行基准测试(benchmarking the efficiency and latency)将是一项宝贵的后续研究,并将完成从自动化发现到实际部署(practical deployment)的循环。
表2:模型性能比较
训练损失(Train Loss)表示最终训练步骤的损失。测试分数(Test Score)是 ARC-Challenge、ARC-Easy、BoolQ、HellaSwag、PIQA、Social IQA 和 WinoGrande 这 7 项任务的平均性能。绿色下标表示相对于 Gated DeltaNet 基线的改进。
| Model Name | 20M params/1B tokens Train Loss↓ | 20M params/1B tokens Test Score ↑ | 340M params/ 1B tokens Train Loss↓ | 340M params/ 1B tokens Test Score ↑ |
|---|---|---|---|---|
| DeltaNet (Baseline) | 4.5749 | 36.23 | 3.5055 | 41.16 |
| Gated DeltaNet (Baseline) | 4.5678 | 36.60 | 3.4768 | 42.10 |
| AdaptiveContextFusionNet | 4.4973 -0.0705 | 37.03 +0.43 | 3.4624 -0.0144 | 42.74 +0.64 |
| AdaptiveEntropyGateNet | 4.4423 -0.1255 | 36.91 +0.31 | 3.4558 -0.0210 | 42.37 +0.27 |
| AdaptiveEntropy Router | 4.3547 -0.2131 | 39.26 +2.66 | 3.4066 -0.0702 | 44.31 +2.21 |
| Adaptive Entropy RouterNet | 4.3326 -0.2352 | 36.94 +0.34 | 3.4298 -0.0470 | 43.25 +1.15 |
| Adaptive FloorGate | 4.4695 -0.0983 | 37.00 +0.40 | 3.4418 -0.0350 | 43.57 +1.47 |
| Adaptive FloorNet-HAF | 4.4002 -0.1676 | 37.03 +0.43 | 3.4241 -0.0527 | 43.59 +1.49 |
| Adaptive FractalGateNet | 4.5484 -0.0194 | 38.43 +1.83 | 3.4351 -0.0417 | 43.84 +1.74 |
| Adaptive FusionNet | 4.3521 -0.2157 | 37.51 +0.91 | 3.4336 -0.0432 | 43.78 +1.68 |
| Adaptive FusionNet-DSI | 4.3781 -0.1897 | 36.63 +0.03 | 3.4270 -0.0498 | 43.39 +1.29 |
| AdaptiveFusionRNet | 4.3940 -0.1738 | 37.03 +0.43 | 3.4086 -0.0682 | 43.73 +1.63 |
| AdaptiveGateNet | 4.4228 -0.1450 | 36.57 -0.03 | 3.4377 -0.0391 | 43.64 +1.54 |
| AdaptiveGateNet-AFP | 4.4198 -0.1480 | 37.80 +1.20 | 3.4193 -0.0575 | 43.88 +1.78 |
| AdaptiveGate Router_X | 4.4126 -0.1552 | 38.69 +2.09 | 3.4114 -0.0654 | 42.68 +0.58 |
| AdaptiveGatedRouter-Hybrid | 4.3335 -0.2343 | 37.74 +1.14 | 3.4060 -0.0708 | 43.56 +1.46 |
| AdaptiveHierGateNet | 4.5096 -0.0582 | 36.71 +0.11 | 3.4433 -0.0335 | 43.44 +1.34 |
| AdaptiveHybridGateNet | 4.3867 -0.1811 | 37.11 +0.51 | 3.4239 -0.0529 | 43.01 +0.91 |
| AdaptiveMixGateNet | 4.3709 -0.1069 | 36.91 +0.31 | 3.4289 -0.0479 | 43.28 +1.18 |
| AdaptiveMix Transformer | 4.4855 -0.0823 | 36.49 -0.11 | 3.4593 -0.0175 | 42.50 +0.40 |
| AdaptivePathRouter | 4.4324 -0.1354 | 38.00 +1.40 | 3.4332 -0.0436 | 42.42 +0.32 |
| AdaptiveSpanGateConv | 4.4431 -0.1247 | 36.74 +0.14 | 3.4247 -0.0521 | 43.90 +1.80 |
| Adaptive TokenGate | 4.4954 -0.0724 | 36.77 +0.17 | 3.4400 -0.0368 | 44.08 +1.98 |
| Adaptive TokenRouter | 4.3745 -0.1033 | 38.63 +2.03 | 3.4238 -0.0530 | 42.56 +0.40 |
| AnnealedPathFusionNet | 4.4564 -0.1114 | 36.83 +0.23 | 3.4472 -0.0296 | 43.73 +1.63 |
| BAMG MemoryGate | 4.4804 -0.0874 | 36.17 -0.43 | 3.4587 -0.0181 | 43.42 +1.32 |
| BlockState FusionNet | 4.3551 -0.2127 | 37.66 +1.06 | 3.4085 -0.0683 | 43.20 +1.10 |
| BoundedTempAnnealNet | 4.4331 -0.1347 | 39.60 +3.00 | 3.4098 -0.0670 | 43.19 +1.09 |
| ContentSharpRouter | 4.3127 -0.2551 | 37.00 +0.40 | 3.4229 -0.0539 | 43.42 +1.32 |
| Conv Fusion Wide31 | 4.4279 -0.1399 | 38.60 +2.00 | 3.4273 -0.0495 | 43.47 +1.37 |
| Convex BlendFloorNet | 4.4021 -0.1057 | 37.80 +1.20 | 3.4265 -0.0503 | 43.54 +1.44 |
| DepthwiseConvPointMixer | 4.4081 -0.1597 | 36.94 +0.34 | 3.4143 -0.0625 | 43.50 +1.40 |
| DualFIR-QuadFusion | 4.3883 -0.1795 | 37.03 +0.43 | 3.4038 -0.0730 | 43.71 +1.61 |
| DualScaleGateNet | 4.4878 -0.0800 | 36.71 +0.11 | 3.4589 -0.0179 | 42.58 +0.48 |
| DualScaleMemory Router | 4.3900 -0.1778 | 37.74 +1.14 | 3.4047 -0.0721 | 44.13 +2.03 |
| DualScaleStatFusionNet | 4.3662 -0.2016 | 36.97 +0.37 | 3.4123 -0.0645 | 44.13 +2.03 |
| DualStagePathGateNet | 4.4596 -0.1082 | 37.63 +1.03 | 3.4428 -0.0340 | 43.41 +1.31 |
| DynFuseFlexGate | 4.3435 -0.2243 | 39.03 +2.43 | 3.4274 -0.0494 | 43.19 +1.09 |
| DynMemGate | 4.3719 -0.1959 | 37.14 +0.54 | 3.4247 -0.0521 | 43.73 +1.63 |
| DynamicMemGateNet | 4.5042 -0.0636 | 37.20 +0.60 | 3.4469 -0.0299 | 42.59 +0.49 |
| EntropyEnhancedMultiScaleGateNet | 4.4217 -0.1461 | 37.37 +0.77 | 3.4044 -0.0724 | 43.36 +1.26 |
| EntropyFlowGateNet | 4.3964 -0.1714 | 36.26 -0.34 | 3.4166 -0.0602 | 43.61 +1.51 |
| EntropyFusionNormX | 4.3963 -0.1715 | 37.26 +0.66 | 3.4592 -0.0176 | 43.99 +1.89 |
| EntropyKLAdaptiveGateNet | 4.3705 -0.1973 | 39.69 +3.09 | 3.4124 -0.0644 | 43.24 +1.14 |
| FusionBalance Transformer | 4.3485 -0.2193 | 38.06 +1.46 | 3.4108 -0.0660 | 43.86 +1.76 |
| FusionConv-AMG | 4.5040 -0.0638 | 37.89 +1.29 | 3.4593 -0.0175 | 42.38 +0.28 |
| FusionFeedback-MixNormNet | 4.3071 -0.2607 | 37.26 +0.66 | 3.4452 -0.0316 | 43.67 +1.57 |
| FusionGATE-HMSR | 4.4316 -0.1362 | 37.71 +1.11 | 3.4286 -0.0482 | 43.83 +1.73 |
| FusionGate AdaptiveNet | 4.4446 -0.1232 | 36.86 +0.26 | 3.4231 -0.0537 | 43.28 +1.18 |
| FusionGate-CAGT | 4.3810 -0.1868 | 37.17 +0.57 | 3.4060 -0.0708 | 43.14 +1.04 |
| FusionGate-HierarchicalRouter | 4.3657 -0.2021 | 38.89 +2.29 | 3.4312 -0.0456 | 43.14 +1.04 |
| FusionGate-MS | 4.3509 -0.2169 | 37.17 +0.57 | 3.4058 -0.0710 | 44.18 +2.08 |
| FusionGate-MS3 | 4.3836 -0.1842 | 38.54 +1.94 | 3.4052 -0.0716 | 43.23 +1.13 |
| FusionGate-MS3E-Hybrid | 4.3828 -0.1850 | 37.09 +0.49 | 3.4251 -0.0517 | 43.59 +1.49 |
| FusionGate-X | 4.3577 -0.2101 | 36.37 -0.23 | 3.4512 -0.0256 | 43.19 +1.09 |
| FusionGate-XL | 4.4634 -0.1044 | 36.77 +0.17 | 3.4536 -0.0232 | 43.70 +1.60 |
| FusionGate-XR | 4.4262 -0.1416 | 36.69 +0.09 | 3.4353 -0.0415 | 44.09 +1.99 |
| FusionGateBR | 4.3475 -0.2203 | 39.23 +2.63 | 3.4229 -0.0539 | 43.39 +1.29 |
| FusionGateMemoryNet | 4.4445 -0.1233 | 37.83 +1.23 | 3.4252 -0.0516 | 42.77 +0.67 |
| FusionGateNet v3 | 4.3889 -0.1789 | 37.14 +0.54 | 3.4064 -0.0704 | 43.89 +1.79 |
| FusionGateX | 4.3619 -0.2059 | 38.80 +2.20 | 3.4298 -0.0470 | 43.37 +1.27 |
| FusionGatedFIRNet | 4.4233 -0.1445 | 39.37 +2.77 | 3.4048 -0.0720 | 44.02 +1.92 |
| FusionLogicNet | 4.3962 -0.1716 | 37.14 +0.54 | 3.4137 -0.0631 | 43.66 +1.56 |
| GateDivergeTransformer | 4.3576 -0.2102 | 39.14 +2.54 | 3.4103 -0.0665 | 44.10 +2.00 |
| GateFlooredResNet | 4.3467 -0.2211 | 38.97 +2.37 | 3.4441 -0.0327 | 42.89 +0.79 |
| GateFusionNet | 4.3957 -0.1721 | 38.91 +2.31 | 3.4415 -0.0353 | 43.66 +1.56 |
| GatedFusionTransformer | 4.3416 -0.2262 | 38.60 +2.00 | 3.4126 -0.0642 | 43.01 +0.91 |
| GroupTempMLP | 4.3948 -0.1730 | 37.97 +1.37 | 3.4243 -0.0525 | 42.84 +0.74 |
| HeadWiseGateNet | 4.4140 -0.1538 | 37.89 +1.29 | 3.4131 -0.0637 | 43.90 +1.80 |
| HierGate-MEM | 4.4518 -0.1160 | 38.09 +1.49 | 3.4398 -0.0370 | 43.76 +1.66 |
| HierarchiMix-Gate | 4.4372 -0.1306 | 36.83 +0.23 | 3.4096 -0.0672 | 43.99 +1.89 |
| HybridCausalRouter | 4.4242 -0.1436 | 38.91 +2.31 | 3.4233 -0.0535 | 43.53 +1.43 |
| HybridFlowNet | 4.3745 -0.1933 | 37.57 +0.97 | 3.4238 -0.0530 | 44.25 +2.15 |
| HybridFusionFloor | 4.3926 -0.1752 | 37.66 +1.06 | 3.4340 -0.0428 | 43.22 +1.12 |
| HybridGateFlow | 4.3653 -0.2025 | 36.63 +0.03 | 3.3998 -0.0770 | 43.78 +1.68 |
| HybridGateTransformer | 4.4780 -0.0898 | 39.03 +2.43 | 3.4656 -0.0112 | 43.74 +1.64 |
| HybridScale-GateNet | 4.4064 -0.1614 | 36.69 +0.09 | 3.4191 -0.0577 | 43.89 +1.79 |
| HybridSparseGateMemoryNet | 4.4204 -0.1474 | 38.29 +1.69 | 3.4469 -0.0299 | 43.49 +1.39 |
| HyenaMAFR | 4.3518 -0.2160 | 40.69 +4.09 | 3.4283 -0.0485 | 43.38 +1.28 |
| HyperRouteFusion | 4.3655 -0.2023 | 36.89 +0.29 | 3.4040 -0.0728 | 43.12 +1.02 |
| LexiFuse-Percept | 4.3432 -0.2246 | 38.14 +1.54 | 3.4327 -0.0441 | 44.02 +1.92 |
| LocalGlobalBlendNet | 4.4653 -0.1025 | 37.54 +0.94 | 3.4361 -0.0407 | 43.56 +1.46 |
| MinFloorRouter | 4.4057 -0.1621 | 37.31 +0.71 | 3.4269 -0.0499 | 43.97 +1.87 |
| OutputAwareMultiScaleRouter | 4.3917 -0.1761 | 37.03 +0.43 | 3.4046 -0.0722 | 44.58 +2.48 |
| ParallelFusionTransformer | 4.3923 -0.1755 | 37.20 +0.60 | 3.4141 -0.0627 | 43.04 +0.94 |
| PathAwareMemoryRouter | 4.3680 -0.1998 | 39.26 +2.66 | 3.4085 -0.0683 | 43.74 +1.64 |
| PathGatedFusionNet | 4.3772 -0.1906 | 37.31 +0.71 | 3.4301 -0.0467 | 43.69 +1.59 |
| PerHeadSimplexRouter | 4.3930 -0.1748 | 36.49 -0.11 | 3.4116 -0.0652 | 43.64 +1.54 |
| QuotaGatedStatNet | 4.4415 -0.1263 | 37.26 +0.66 | 3.4163 -0.0605 | 42.64 +0.54 |
| ResConvGate | 4.3881 -0.1797 | 37.11 +0.51 | 3.4418 -0.0350 | 42.72 +0.62 |
| ResGate MS FusionNet | 4.4848 -0.0830 | 38.69 +2.09 | 3.4126 -0.0642 | 42.76 +0.66 |
| ResiFuse-CausalGater | 4.3674 -0.2004 | 36.23 -0.37 | 3.4243 -0.0525 | 43.03 +0.93 |
| SparseGateDelta | 4.4503 -0.1175 | 37.31 +0.71 | 3.4433 -0.0335 | 43.40 +1.30 |
| SparseTempGateNet | 4.4493 -0.1185 | 37.03 +0.43 | 3.4693 -0.0075 | 43.08 +0.98 |
| SpectralContextMixer | 5.1512 -0.5834 | 36.17 -0.43 | 3.4695 -0.0073 | 43.41 +1.31 |
| StatGateRouter | 4.4155 -0.1523 | 36.69 +0.09 | 3.4465 -0.0303 | 43.43 +1.33 |
| StreamAwareRouter | 4.3508 -0.2170 | 37.97 +1.37 | 3.4179 -0.0589 | 43.62 +1.52 |
| SynerFuse-LGX | 4.3611 -0.2067 | 39.80 +3.20 | 3.4243 -0.0525 | 43.67 +1.57 |
| TempMixAnnealRouter | 4.3416 -0.2262 | 38.46 +1.86 | 3.4014 -0.0754 | 44.01 +1.91 |
| TokenPruneRouter | 4.3754 -0.1924 | 39.40 +2.80 | 3.4253 -0.0515 | 42.69 +0.59 |
| TokenScaleRouter | 4.4552 -0.1126 | 39.31 +2.71 | 3.4274 -0.0494 | 42.91 +0.81 |
| TriScale-GatedFusion | 4.3647 -0.2031 | 36.69 +0.09 | 3.4027 -0.0741 | 43.70 +1.60 |