以太坊之详解默克尔压缩前缀树
1. 基础数据结构
在深入以太坊状态树的实现之前,有必要先理解其底层数据结构:Merkle Patricia Trie(MPT) —— 一种结合了前缀树(Trie)、压缩前缀树(Patricia Trie) 和默克尔树(Merkle Tree) 特性的混合结构。它不仅是高效键值存储的载体,也是以太坊实现“状态可验证性”和“轻节点同步”的核心。
1.1 前缀树(Trie)
Trie,又称字典树或前缀树,是一种有序树结构,常用于存储关联数组,其中键通常是字符串。与二叉查找树不同,Trie 的键并非直接存储在节点中,而是通过节点在树中的路径隐式表达 —— 每个节点代表一个字符,从根节点到某节点的路径拼接起来即为该节点所代表的键。
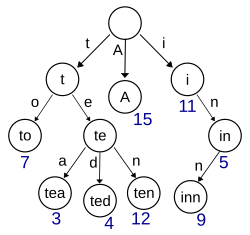
上图展示了一个保存 8 个键的 Trie 结构:“A”, “to”, “tea”, “ted”, “ten”, “i”, “in”, “inn”。
图中,键标注在节点路径上(实际实现中通常不显式存储),值标注在叶子节点下方。只有部分节点(通常是叶子或具有值的中间节点)才关联具体值。
Trie 的优势在于支持高效的前缀匹配和动态插入/删除,但缺点也很明显:空间浪费严重。例如,若键很长且无公共前缀,树会变得非常深且稀疏。
1.2 压缩前缀树(Patricia Trie / Radix Trie)
为了解决标准 Trie 的空间低效问题,Patricia Trie(Practical Algorithm To Retrieve Information Coded In Alphanumeric) 应运而生,也称 Radix Trie 或压缩前缀树。
其核心思想是:合并路径上无分叉的连续节点,从而压缩树的深度和节点数量。每个节点可以代表一个字符(r=256)或一个比特位(r=2),甚至多个字节 —— 取决于基数(radix)的选择。
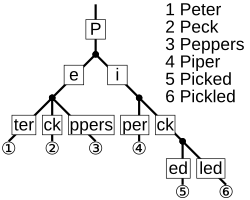
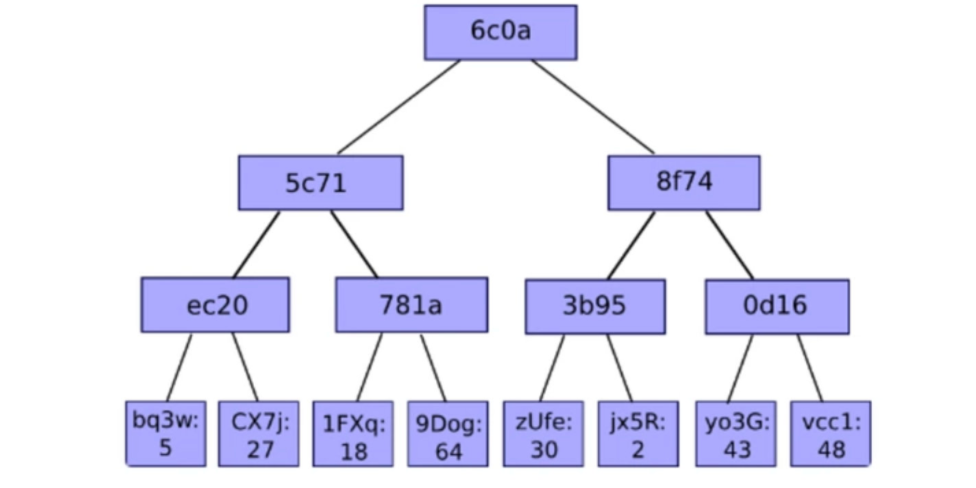
图中存储的键值对示例:
6c0a5c71ec20bq3w→ 56c0a5c71ec20CX7j→ 276c0a5c71781a1FXq→ 186c0a5c71781a9Dog→ 646c0a8f743b95zUfe→ 306c0a8f743b95jx5R→ 26c0a8f740d16y03G→ 436c0a8f740d16vcc1→ 48
为什么 Patricia Trie 仍不够?
在以太坊中,参与树构建的键通常是 32 字节的哈希值(如 Keccak256),转换为十六进制字符串后长度为 64。这意味着:
- 树的最大深度可达 64(若按字符逐层展开);
- 每个节点需存储路径、子节点指针、值等元数据;
- 大量路径节点无实际分叉,却仍需独立存储;
- 频繁的状态更新会导致大量节点写入,IO 和存储开销巨大。
因此,直接使用 Patricia Trie 无法满足以太坊对高效更新、快速验证、轻量同步的需求。
1.3 默克尔树(Merkle Tree)
默克尔树(Merkle Tree),也常被称为哈希树(Hash Tree)。它的核心目的不是高效地存储和查找数据,而是为大规模数据提供一个高效、安全的完整性验证方法。
默克尔树的结构通常是二叉树(或多叉树),其特点如下:
- 叶子节点:存储数据块的哈希值。
- 非叶子节点:存储其所有子节点哈希值的哈希值。
- 根节点:最终计算出的顶部哈希,称为默克尔根(Merkle Root)。
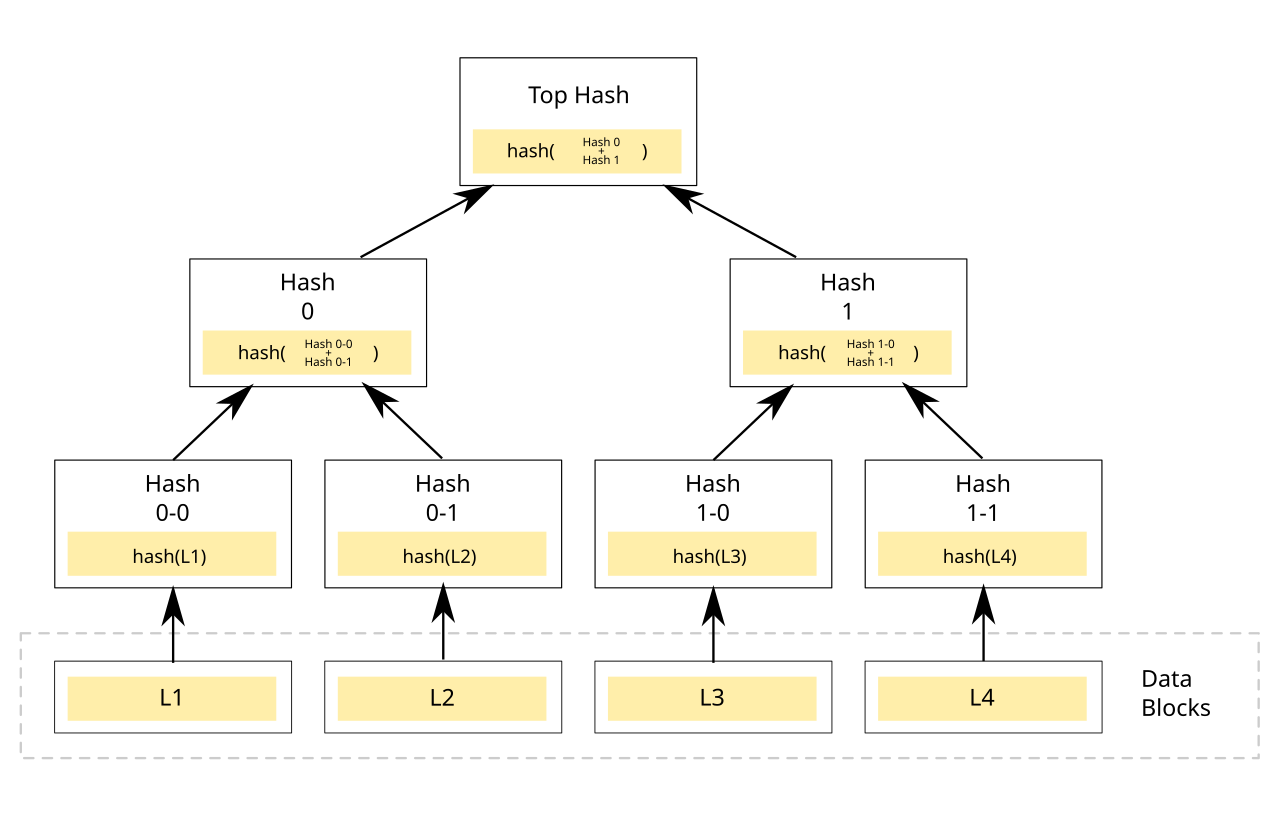
图4:默克尔树的构建过程
构建过程是自底向上的:
- 将底层的数据块(如 L1, L2, L3, L4)分别进行哈希计算,得到叶子节点
Hash 0-0,Hash 0-1,Hash 1-0,Hash 1-1。 - 将相邻的叶子节点两两配对,计算它们的父节点的哈希值。例如,
Hash 0 = Hash(Hash 0-0 + Hash 0-1)。 - 重复这个过程,直到计算出唯一的根哈希
Top Hash。
默克尔树具有以下关键特性:
- 高效的数据完整性验证:要验证整个数据集是否被篡改,只需要比较新计算出的默克尔根与可信的旧默克尔根是否一致即可。这比逐一比较所有数据块要快得多。
- 高效的部分数据验证(默克尔证明):这是默克尔树最强大的功能。如果我们想向别人证明某个数据块(如 L1)确实存在于原始数据集中,我们不需要发送整个数据集。我们只需要发送 L1 本身,以及从 L1 到根节点的路径上所有“兄弟”节点的哈希(在这个例子中是
Hash 0-1和Hash 1)。接收方可以用这些信息独立地重新计算出根哈希,并与已知的根哈希进行比对。这个验证过程所需的数据量(称为默克尔证明,Merkle Proof)非常小,与数据集的总大小无关,只与树的深度对数相关。 - 快速定位不一致的数据:如果根哈希不匹配,可以通过逐层向下比较哈希值,快速定位到被篡改的数据块。
这个“默克尔证明”的特性对于区块链(尤其是轻节点)来说是革命性的。轻节点不需要下载所有区块数据,它只需存储区块头(其中包含默克尔根),就可以通过默克尔证明来验证某笔交易是否真实存在于某个区块中。
1.4 以太坊的改进:Merkle Patricia Trie(MPT)
以太坊没有直接使用上述任一结构,而是创造性地将三者融合,构建了 Merkle Patricia Trie(MPT):
以太坊的目标是创建一个既能高效存储和检索键值对,又能提供强大加密学证明的数据结构。
- 只用 Radix Trie?可以高效地存取数据,但无法为数据提供加密学证明。没法生成一个代表整个数据集状态的、唯一的、可验证的“指纹”。
- 只用 Merkle Tree?可以验证数据,但它的结构不利于高效地查找、更新或删除单个键值对。
以太坊的解决方案是:将二者合二为一,创造出默克尔帕特里夏树(Merkle Patricia Trie)。
MPT 本质上是一个 Radix Trie,但它增加了 Merkle Tree 的特性:
- 路径即键,节点存值:它遵循 Radix Trie 的规则,通过路径来表示键,并通过压缩来节省空间。
- 节点间通过哈希链接:在 MPT 中,一个父节点并不直接存储指向其子节点的内存指针,而是存储子节点的哈希值。
- 根哈希代表全局状态:对树中所有节点进行类似的哈希计算,最终在根节点会得到一个唯一的哈希值。这个哈希就是我们常听到的状态根(State Root)、交易根(Transactions Root)或收据根(Receipts Root)。
通过这种方式,MPT 完美地结合了三者的优点:
- Trie 的键值映射能力。
- Radix Trie 的空间效率。
- Merkle Tree 的加密学验证能力。
树中任何数据的微小变动,都会导致其父节点的哈希改变,这种改变会一直向上传播,最终形成一个完全不同的根哈希。这使得以太坊的整个状态(所有账户的余额、代码、存储等)都可以被一个仅有32字节的哈希值所代表和担保。同时,利用默克尔证明的原理,任何人都可以高效地验证状态树中的一小部分信息(例如,“A账户的余额确实是100 ETH”),而无需同步整个状态数据库。
2. 源码阅读:深入以太坊 Merkle Patricia Trie 的实现
理解了 Merkle Patricia Trie (MPT) 的核心概念之后,接下来看源码,看看这些抽象概念是如何具体实现的。MPT 实现主要位于 trie 或 core/state/trie 包中。
2.1 核心数据结构
2.1.1 核心数据结构
-
分支节点
fullNode:- 核心是
Children [17]node,表示一个分支节点(Branch Node)。Children[0]到Children[15]:对应十六进制的 0 到 F。每个元素指向一个子节点。当遍历 MPT 路径时,每一位十六进制字符决定了接下来进入哪个子节点。Children[16]:这个特殊的槽位用于存储当前分支节点自身可能携带的值。换句话说,如果一个键值对的键路径恰好走到了这个 fullNode 就结束了,那么这个键对应的值就存放在这里。(后面代码部分会贴示例)
flags nodeFlag: 用于标记节点状态,如是否为脏节点(dirty)、是否已哈希、缓存代数等,服务于节点缓存与持久化机制。
- 核心是
-
扩展节点或叶子节点
shortNode:Key []byte: 存储这个节点的路径段。这个Key并不是原始的哈希值键的一部分,而是经过十六进制前缀(Hex-Prefix, HP)编码后的路径片段。Val node:- 如果
shortNode是一个扩展节点(Extension Node),Val会指向它的下一个子节点(可能是一个fullNode,shortNode或者hashNode)。它的作用是压缩一条公共前缀路径。 - 如果
shortNode是一个叶子节点(Leaf Node),Val直接存储了该路径对应的值,(一个 valueNode,也就是[]byte)。这个值是经过 RLP 编码的。
- 如果
-
hashNode(哈希节点):- 代表一个已经持久化到数据库的子节点,或者一个通过其哈希值引用的节点。当访问它时,需要从数据库中加载其真实内容。这是 Merkle Tree 特性的核心体现:节点不再直接存储子节点,而是存储子节点的哈希,从而形成加密学上的链接。
-
valueNode(值节点):- 同样是一个
[]byte。它存储的是键值对中,具体键对应的值。在 MPT 中,所有的值都是原始的字节数组。
- 同样是一个
hashNode 和 valueNode 均为底层数据类型,不包含子结构,前者用于引用,后者用于存储最终值。
// trie/node.go
type (
fullNode struct {
Children [17]node // Actual trie node data to encode/decode (needs custom encoder)
flags nodeFlag
}
shortNode struct {
Key []byte
Val node
flags nodeFlag
}
hashNode []byte
valueNode []byte
// fullnodeEncoder is a type used exclusively for encoding fullNode.
// Briefly instantiating a fullnodeEncoder and initializing with
// existing slices is less memory intense than using the fullNode type.
fullnodeEncoder struct {
Children [17][]byte
}
// extNodeEncoder is a type used exclusively for encoding extension node.
// Briefly instantiating a extNodeEncoder and initializing with existing
// slices is less memory intense than using the shortNode type.
extNodeEncoder struct {
Key []byte
Val []byte
}
// leafNodeEncoder is a type used exclusively for encoding leaf node.
leafNodeEncoder struct {
Key []byte
Val []byte
}
)2.1.2 十六进制前缀编码(Hex-Prefix Encoding)
在 shortNode 中,它的 Key 字段是经过“十六进制前缀编码”的。需要这个编码的原因是 shortNode 既可以表示扩展节点,也可以表示叶子节点,所以需要一种方式来进行区分。同时,路径的长度可能是奇数或偶数,也需要区分。十六进制前缀编码也称为HP编码。通过在路径前添加一个四位元(nibble)的前缀来同时解决这两个问题。
原始路径被看作是一系列的四位元(nibbles)。
| 路径长度 | 节点类型 | 前缀 (二进制) | 前缀 (十六进制) |
|---|---|---|---|
| 偶数 | 扩展节点 | 0000 | 0x0 |
| 奇数 | 扩展节点 | 0001 | 0x1 |
| 偶数 | 叶子节点 | 0010 | 0x2 |
| 奇数 | 叶子节点 | 0011 | 0x3 |
HP 编码的核心是为原始路径(nibbles 数组)添加一个单字节的前缀。这个前缀字节由两部分组成:
- 高4位 (High Nibble): 包含上表所示的标志位(
0x0,0x1,0x2,0x3)。 - 低4位 (Low Nibble): 根据路径长度的奇偶性而定。
组合规则如下:
-
如果路径的
nibble数量是奇数:- 将标志
nibble(0x1或0x3)作为前缀字节的高4位。 - 将原始路径的第一个
nibble作为前缀字节的低4位。 - 将这个合成的前缀字节与剩余的路径字节拼接起来。
- 示例 (奇数叶子节点, 路径
12345):- 标志
nibble:0x3 - 路径
nibbles:[1, 2, 3, 4, 5] - 第一个字节:
0x3和0x1合并 ->0x31 - 剩余路径:
[2, 3, 4, 5]->0x23,0x45 - 最终编码:
0x312345
- 标志
- 将标志
-
如果路径的
nibble数量是偶数:- 将标志
nibble(0x0或0x2)作为前缀字节的高4位。 - 用一个
0x0的nibble作为填充物,放在前缀字节的低4位。 - 将这个合成的前缀字节与完整的原始路径字节拼接起来。
- 示例 (偶数扩展节点, 路径
1234):- 标志
nibble:0x0 - 路径
nibbles:[1, 2, 3, 4] - 第一个字节:
0x0和0x0(填充) 合并 ->0x00 - 完整路径:
[1, 2, 3, 4]->0x12,0x34 - 最终编码:
0x001234
- 标志
- 将标志
这种编码方式非常巧妙,仅通过第一个字节就能解码出节点类型和路径的奇偶性,为后续的遍历和解析提供了必要信息。
// trie/encoding.go
func hexToCompact(hex []byte) []byte {
terminator := byte(0)
if hasTerm(hex) {
terminator = 1
hex = hex[:len(hex)-1]
}
buf := make([]byte, len(hex)/2+1)
buf[0] = terminator << 5 // the flag byte
if len(hex)&1 == 1 {
buf[0] |= 1 << 4 // odd flag
buf[0] |= hex[0] // first nibble is contained in the first byte
hex = hex[1:]
}
decodeNibbles(hex, buf[1:])
return buf
}2.2 Trie 结构
Trie 结构体是与 MPT 交互的入口点。它封装了根节点、数据库连接以及用于管理状态和缓存的各种标志。Get, Update, Delete 等方法,都是定义在 Trie 类型上的。
// trie/trie.go
type Trie struct {
root node
owner common.Hash
// Flag whether the commit operation is already performed. If so the
// trie is not usable(latest states is invisible).
committed bool
// Keep track of the number leaves which have been inserted since the last
// hashing operation. This number will not directly map to the number of
// actually unhashed nodes.
unhashed int
// uncommitted is the number of updates since last commit.
uncommitted int
// reader is the handler trie can retrieve nodes from.
reader *Reader
// Various tracers for capturing the modifications to trie
opTracer *opTracer
prevalueTracer *PrevalueTracer
}几个关键字段:
root node: 这是 Trie 的根节点。所有的查找、插入、删除操作都从这里开始。root的哈希值就是整个 Trie 的 Merkle Root,代表了整个键值对集合的状态快照。reader *Reader: 这是与底层数据库交互的接口。当遍历过程中遇到一个hashNode时,Trie 会通过这个reader从数据库(如 LevelDB)中加载出完整的节点数据。这是实现**懒加载(Lazy Loading)**的关键,Trie 不需要一次性把所有节点都加载到内存中。owner common.Hash: 当 MPT 用于存储账户状态时,owner可以是账户地址的哈希。它主要用于数据库内部的命名空间或日志记录,以区分不同的 Trie。committed, unhashed, uncommitted: 这些字段主要用于状态管理和性能优化。它们帮助 Trie 跟踪哪些节点是“脏”的(即被修改过但尚未写入数据库),并决定何时需要重新计算哈希并向数据库提交更新。
2.3 核心操作一:Get
Get 方法是与 Trie 交互最基本的方式。它的逻辑很纯粹:给定一个 key,顺着 root 节点一路向下查找,直到找到对应的值或者确认 key 不存在。
func (t *Trie) Get(key []byte) ([]byte, error) {
// Short circuit if the trie is already committed and not usable.
if t.committed {
return nil, ErrCommitted
}
// 从 root 节点开始,key 转换为 nibbles 路径,从第 0 个位置开始查找
value, newroot, didResolve, err := t.get(t.root, keybytesToHex(key), 0)
if err == nil && didResolve {
t.root = newroot
}
return value, err
}公开的 Trie.Get(key []byte) ([]byte, error) 方法其实是一个入口,其核心逻辑委托给了内部的 trie.get(node, key, pos) 方法来递归执行。
func (t *Trie) get(origNode node, key []byte, pos int) (value []byte, newnode node, didResolve bool, err error) {
switch n := (origNode).(type) {
case nil:
return nil, nil, false, nil
case valueNode:
return n, n, false, nil
case *shortNode:
if !bytes.HasPrefix(key[pos:], n.Key) {
// key not found in trie
return nil, n, false, nil
}
value, newnode, didResolve, err = t.get(n.Val, key, pos+len(n.Key))
if err == nil && didResolve {
n.Val = newnode
}
return value, n, didResolve, err
case *fullNode:
value, newnode, didResolve, err = t.get(n.Children[key[pos]], key, pos+1)
if err == nil && didResolve {
n.Children[key[pos]] = newnode
}
return value, n, didResolve, err
case hashNode:
child, err := t.resolveAndTrack(n, key[:pos])
if err != nil {
return nil, n, true, err
}
value, newnode, _, err := t.get(child, key, pos)
return value, newnode, true, err
default:
panic(fmt.Sprintf("%T: invalid node: %v", origNode, origNode))
}
}下面我们来拆解 trie.get 的递归查找过程,整个过程是一个大型的 switch 语句,根据当前节点的类型进行不同的处理。
-
case nil: 这是递归的终点。如果在路径上遇到一个nil节点,说明查找的键不存在,函数直接返回nil。 -
case valueNode: 这也是一个递归的终点。如果直接遇到了一个valueNode,说明它就是与当前路径完全匹配的最终值。函数直接返回这个值。这种情况通常发生在shortNode(叶子节点)的Val指向一个valueNode后,在下一层递归中匹配到。 -
case *shortNode: 这是处理路径压缩的关键。if !bytes.HasPrefix(key[pos:], n.Key): 首先,检查当前剩余的查找路径key[pos:]是否以该shortNode的路径n.Key作为前缀。如果不是,说明路径在此处分叉,键不存在,返回nil。t.get(n.Val, key, pos+len(n.Key)): 如果前缀匹配成功,说明已经走过了shortNode所代表的路径段。接下来,需要深入到它的子节点n.Val中继续查找。因此,函数进行递归调用,并将查找位置pos向前推进shortNode路径的长度。
-
case *fullNode: 这是处理路径分支的地方。t.get(n.Children[key[pos]], key, pos+1): 逻辑非常直接:从当前查找路径key中取出下一个 nibble,即key[pos]。这个 nibble 的值(0-15)正好对应Children数组的索引。然后,以Children数组中该索引位置的子节点为起点,继续递归查找,同时将查找位置pos向前移动一位。
-
case hashNode: 这是实现懒加载的核心。child, err := t.resolveAndTrack(n, key[:pos]): 当遇到一个hashNode时,它只是一个指向数据库中完整节点的“指针”。函数会调用resolveAndTrack,根据哈希值n从数据库中加载出完整的节点数据(一个shortNode或fullNode)。t.get(child, key, pos): 一旦节点被成功加载到内存,get函数就会在这个新的、完整的child节点上重新开始查找过程,参数和位置pos保持不变。
最后,代码中的 if err == nil && didResolve 逻辑,用于在懒加载 (resolve) 发生后,将内存中的 hashNode 替换为新加载的完整节点。这是一种缓存优化,避免了对同一个 hashNode 的重复数据库读取。
2.4 核心操作二:Insert (插入/更新)
insert 函数负责向Trie中添加或更新一个键值对。这个过程最复杂的地方在于如何处理路径冲突,这通常需要 拆分(split) 现有节点来创造新的分支。
接下来看 insert 函数在遇到不同节点类型时的递归逻辑:
-
case nil: 这是最简单的情况。如果在遍历时遇到一个nil节点,意味着这里是一个“空位”,可以直接插入。系统会创建一个新的shortNode(叶子节点),其Key是剩余的路径,Val是要存储的值。 -
case *fullNode: 遇到分支节点时,逻辑很直接。根据当前key的第一个nibble,选择Children数组中对应的分支,然后将剩余的key传入,对该分支进行递归insert。 -
case hashNode: 和get操作一样,遇到hashNode时,首先会调用resolve将其从数据库中加载为完整的节点,然后在加载出的新节点上重新执行insert操作。 -
case *shortNode: 这是insert操作中最核心、最复杂的逻辑。当插入路径与一个shortNode发生交集时:- 计算共同前缀:首先,计算要插入的
key和当前shortNode.Key之间的共同前缀长度matchlen。 - 完全匹配 (
matchlen == len(n.Key)): 如果shortNode的路径就是要插入key的前缀,说明路径方向正确,只需对shortNode的子节点n.Val继续进行递归insert。 - 部分匹配 (
matchlen < len(n.Key)): 这是最关键的情况:路径在此处发生分叉。原有的shortNode必须被拆分,以容纳新的路径分支。- 创建一个新的
fullNode(分支节点)来替代原来的shortNode。 - 原
shortNode剩余的路径(n.Key[matchlen+1:])及其值n.Val,会被插入到新fullNode的一个槽位中。 - 要插入的
key剩余的路径(key[matchlen+1:])及其value,会被插入到新fullNode的另一个槽位中。 - 最后,如果共同前缀
matchlen大于0,会创建一个新的shortNode,其Key是这个共同前缀,其Val指向刚刚创建的那个fullNode。这个新的shortNode会取代原来节点的位置。
- 创建一个新的
- 计算共同前缀:首先,计算要插入的
这个“拆分-替换”的过程是MPT能够动态适应任意键值对集合的关键。
完整实现:
func (t *Trie) insert(n node, prefix, key []byte, value node) (bool, node, error) {
if len(key) == 0 {
if v, ok := n.(valueNode); ok {
return !bytes.Equal(v, value.(valueNode)), value, nil
}
return true, value, nil
}
switch n := n.(type) {
case *shortNode:
matchlen := prefixLen(key, n.Key)
// If the whole key matches, keep this short node as is
// and only update the value.
if matchlen == len(n.Key) {
dirty, nn, err := t.insert(n.Val, append(prefix, key[:matchlen]...), key[matchlen:], value)
if !dirty || err != nil {
return false, n, err
}
return true, &shortNode{n.Key, nn, t.newFlag()}, nil
}
// Otherwise branch out at the index where they differ.
branch := &fullNode{flags: t.newFlag()}
var err error
_, branch.Children[n.Key[matchlen]], err = t.insert(nil, append(prefix, n.Key[:matchlen+1]...), n.Key[matchlen+1:], n.Val)
if err != nil {
return false, nil, err
}
_, branch.Children[key[matchlen]], err = t.insert(nil, append(prefix, key[:matchlen+1]...), key[matchlen+1:], value)
if err != nil {
return false, nil, err
}
// Replace this shortNode with the branch if it occurs at index 0.
if matchlen == 0 {
return true, branch, nil
}
// New branch node is created as a child of the original short node.
// Track the newly inserted node in the tracer. The node identifier
// passed is the path from the root node.
t.opTracer.onInsert(append(prefix, key[:matchlen]...))
// Replace it with a short node leading up to the branch.
return true, &shortNode{key[:matchlen], branch, t.newFlag()}, nil
case *fullNode:
dirty, nn, err := t.insert(n.Children[key[0]], append(prefix, key[0]), key[1:], value)
if !dirty || err != nil {
return false, n, err
}
n.flags = t.newFlag()
n.Children[key[0]] = nn
return true, n, nil
case nil:
// New short node is created and track it in the tracer. The node identifier
// passed is the path from the root node. Note the valueNode won't be tracked
// since it's always embedded in its parent.
t.opTracer.onInsert(prefix)
return true, &shortNode{key, value, t.newFlag()}, nil
case hashNode:
// We've hit a part of the trie that isn't loaded yet. Load
// the node and insert into it. This leaves all child nodes on
// the path to the value in the trie.
rn, err := t.resolveAndTrack(n, prefix)
if err != nil {
return false, nil, err
}
dirty, nn, err := t.insert(rn, prefix, key, value)
if !dirty || err != nil {
return false, rn, err
}
return true, nn, nil
default:
panic(fmt.Sprintf("%T: invalid node: %v", n, n))
}
}详解:一个插入示例
这里主要写shortNode部分:
shortNode 的处理是 insert 操作中最核心、最能体现Trie压缩思想的部分。当插入的新路径与一个已存在的 shortNode 路径发生交集时,Trie必须进行 拆分 来创造新的分支。
假设Trie中目前只有一个键值对:
- 键:
"cat"(其nibbles序列为[6, 3, 6, 1, 7, 4]) - 值:
value_A
此时,Trie的结构是(为简化,假设这是根节点):
root -> shortNode{ Key: [6, 3, 6, 1, 7, 4], Val: value_A } (这是一个叶子节点)
现在,我们要插入一个新的键值对:
- 键:
"car"(其nibbles序列为[6, 3, 6, 1, 7, 2]) - 值:
value_B
insert 函数会执行以下步骤:
-
计算共同前缀: 比较新键的路径
[6, 3, 6, 1, 7, 2]和当前shortNode的路径[6, 3, 6, 1, 7, 4]。- 它们的共同前缀是
[6, 3, 6, 1, 7]。共同前缀长度matchlen为 5。 - 在第 6 个
nibble处 (4vs2),路径出现分歧。
- 它们的共同前缀是
-
创建分支节点 (
fullNode): 由于路径在此处分叉,系统必须创建一个新的fullNode作为“交叉路口”。 -
拆分和重组: 原来的叶子节点 (
shortNode) 将被一个新的扩展节点 (shortNode) 和一个新的分支节点 (fullNode) 的组合所取代。-
新的父节点 (扩展节点): 这个节点代表了共同的路径。
Key:[6, 3, 6, 1, 7](共同前缀)Val: 指向下面新创建的fullNode。
-
新的
fullNode(分支节点): 这个节点是新的“交叉路口”,它自身没有路径。- 对于原来的键
"cat",分叉后的下一个nibble是4。原始路径的剩余部分 (n.Key[matchlen+1:]) 是空的,所以它的值value_A会被直接插入到Children数组的第4个槽位。更准确地说,Children[4]会指向一个valueNode,其内容为value_A。 - 对于新的键
"car",分叉后的下一个nibble是2。新路径的剩余部分也是空的,所以它的值value_B会被插入到Children数组的第2个槽位。Children[2]会指向一个valueNode,其内容为value_B。 - 其他
Children槽位都为nil。
- 对于原来的键
-
总结:变化前后对比
插入前:
root -> shortNode{ Key: [6, 3, 6, 1, 7, 4], Val: value_A, Type: Leaf }插入后:
root -> shortNode{ Key: [6, 3, 6, 1, 7], Val: ptr_to_fullNode, Type: Extension }
|
|
V
fullNode{
Children: [
nil, nil,
ptr_to_value_B, // index 2
nil,
ptr_to_value_A, // index 4
nil, ..., nil // other 15 slots are nil
]
}通过这个“拆分-重组”的过程,Trie能够在不重复存储共同前缀的情况下,高效地管理两条不同的路径。这正是默克尔帕特里夏树(Merkle Patricia Trie)空间效率高的根本原因。
2.5 核心操作三:Delete (删除)
删除操作可以看作是插入的逆过程。当一个键值对被删除后,Trie需要进行 简化(simplify) 和 合并(merge) 操作,以保持其最高效的压缩形态。
delete 的核心逻辑是:在递归删除路径上的节点后,返回时检查当前节点是否需要简化。
-
case *shortNode:- 路径不匹配:如果要删除的
key与shortNode.Key不匹配,说明该key不存在,直接返回。 - 完全匹配:如果要删除的
key与shortNode的路径和值都匹配,则直接删除该节点(返回nil)。 - 部分匹配:如果
shortNode.Key只是key的一部分,则对子节点n.Val递归调用delete。- 合并子节点:在子节点删除完成后,如果子节点变成了一个只含有一条路径的
shortNode,那么父子两个shortNode就应该合并成一个,避免出现shortNode嵌套shortNode的冗余结构。
- 合并子节点:在子节点删除完成后,如果子节点变成了一个只含有一条路径的
- 路径不匹配:如果要删除的
-
case *fullNode:- 首先,根据
key的下一个nibble找到对应的子节点,并对其递归调用delete。 - 检查简化:在子节点被删除后,需要检查当前的
fullNode。如果它只剩下一个非空的子节点,那么多达16路的分支就不再有意义了。- 此时,这个
fullNode必须被简化为一个shortNode。新的shortNode会包含剩下的那个唯一子节点的路径和值,从而大大压缩树的结构。
- 此时,这个
- 首先,根据
-
case hashNode/case nil:- 与
insert类似,hashNode需要先从数据库加载再执行删除。nil则表示路径不存在,直接返回。
- 与
总而言之,删除操作通过递归地简化和合并节点,确保Trie在删除数据后依然保持最小和最优的结构。
完整实现:
func (t *Trie) delete(n node, prefix, key []byte) (bool, node, error) {
switch n := n.(type) {
case *shortNode:
matchlen := prefixLen(key, n.Key)
if matchlen < len(n.Key) {
return false, n, nil // don't replace n on mismatch
}
if matchlen == len(key) {
// The matched short node is deleted entirely and track
// it in the deletion set. The same the valueNode doesn't
// need to be tracked at all since it's always embedded.
t.opTracer.onDelete(prefix)
return true, nil, nil // remove n entirely for whole matches
}
// The key is longer than n.Key. Remove the remaining suffix
// from the subtrie. Child can never be nil here since the
// subtrie must contain at least two other values with keys
// longer than n.Key.
dirty, child, err := t.delete(n.Val, append(prefix, key[:len(n.Key)]...), key[len(n.Key):])
if !dirty || err != nil {
return false, n, err
}
switch child := child.(type) {
case *shortNode:
// The child shortNode is merged into its parent, track
// is deleted as well.
t.opTracer.onDelete(append(prefix, n.Key...))
// Deleting from the subtrie reduced it to another
// short node. Merge the nodes to avoid creating a
// shortNode{..., shortNode{...}}. Use concat (which
// always creates a new slice) instead of append to
// avoid modifying n.Key since it might be shared with
// other nodes.
return true, &shortNode{slices.Concat(n.Key, child.Key), child.Val, t.newFlag()}, nil
default:
return true, &shortNode{n.Key, child, t.newFlag()}, nil
}
case *fullNode:
dirty, nn, err := t.delete(n.Children[key[0]], append(prefix, key[0]), key[1:])
if !dirty || err != nil {
return false, n, err
}
n.flags = t.newFlag()
n.Children[key[0]] = nn
// Because n is a full node, it must've contained at least two children
// before the delete operation. If the new child value is non-nil, n still
// has at least two children after the deletion, and cannot be reduced to
// a short node.
if nn != nil {
return true, n, nil
}
// Reduction:
// Check how many non-nil entries are left after deleting and
// reduce the full node to a short node if only one entry is
// left. Since n must've contained at least two children
// before deletion (otherwise it would not be a full node) n
// can never be reduced to nil.
//
// When the loop is done, pos contains the index of the single
// value that is left in n or -2 if n contains at least two
// values.
pos := -1
for i, cld := range &n.Children {
if cld != nil {
if pos == -1 {
pos = i
} else {
pos = -2
break
}
}
}
if pos >= 0 {
if pos != 16 {
// If the remaining entry is a short node, it replaces
// n and its key gets the missing nibble tacked to the
// front. This avoids creating an invalid
// shortNode{..., shortNode{...}}. Since the entry
// might not be loaded yet, resolve it just for this
// check.
cnode, err := t.resolve(n.Children[pos], append(prefix, byte(pos)))
if err != nil {
return false, nil, err
}
if cnode, ok := cnode.(*shortNode); ok {
// Replace the entire full node with the short node.
// Mark the original short node as deleted since the
// value is embedded into the parent now.
t.opTracer.onDelete(append(prefix, byte(pos)))
k := append([]byte{byte(pos)}, cnode.Key...)
return true, &shortNode{k, cnode.Val, t.newFlag()}, nil
}
}
// Otherwise, n is replaced by a one-nibble short node
// containing the child.
return true, &shortNode{[]byte{byte(pos)}, n.Children[pos], t.newFlag()}, nil
}
// n still contains at least two values and cannot be reduced.
return true, n, nil
case valueNode:
return true, nil, nil
case nil:
return false, nil, nil
case hashNode:
// We've hit a part of the trie that isn't loaded yet. Load
// the node and delete from it. This leaves all child nodes on
// the path to the value in the trie.
rn, err := t.resolveAndTrack(n, prefix)
if err != nil {
return false, nil, err
}
dirty, nn, err := t.delete(rn, prefix, key)
if !dirty || err != nil {
return false, rn, err
}
return true, nn, nil
default:
panic(fmt.Sprintf("%T: invalid node: %v (%v)", n, n, key))
}
}2.6 哈希与持久化:从内存到数据库
到目前为止,get、insert和delete操作都还停留在内存层面。如果程序关闭,所有的修改都会丢失。Trie的“默克尔(Merkle)”特性,正是通过哈希(Hashing) 和 **持久化(Persistence)**来确保数据完整性和永久性的。
这个过程的核心思想是:自底向上地计算每个节点的哈希值,最终得到一个唯一的根哈希(Merkle Root) ,它代表了整个Trie在某一时刻的完整状态快照。
2.6.1 节点的哈希
Trie中的每一个节点(fullNode, shortNode)都可以被序列化和哈希。具体过程如下:
-
序列化 (RLP编码): 节点的内容首先会被RLP (Recursive Length Prefix) 编码成一个字节数组。RLP是以太坊中用于序列化对象的主要编码方式。
- 对于
fullNode,它的17个子节点(的哈希或内容)会被编码成一个列表。 - 对于
shortNode,它的Key(经过HP编码)和Val会被编码成一个包含两个元素的列表。
- 对于
-
计算哈希: 序列化后的字节数组会通过Keccak-256哈希算法计算出一个32字节的哈希值。
这个哈希值就是该节点在数据库中的“身份证”。当一个父节点需要引用子节点时,它存储的不是子节点的完整内容,而是这个哈希值(也就是我们之前看到的hashNode)。
2.6.2 Commit 操作:提交变更
Commit 函数是固化Trie所有变更的最终入口。其核心职责是计算出最终的默克尔根哈希,并准备好所有需要写入数据库的节点数据。
Commit 的执行流程可分解为以下几个关键步骤:
-
处理空Trie: 函数首先通过
if t.root == nil检查Trie是否为空。空Trie有两种可能:它一直为空,或者其所有节点都恰好被删除了。代码会处理这两种情况,并返回以太坊中预定义的空根哈希types.EmptyRootHash。 -
预计算根哈希:
rootHash := t.Hash()是一个关键的预处理步骤。该方法会自底向上地递归遍历所有“脏”节点(被修改过的节点),并计算出它们的哈希值。此步骤执行完毕后,内存中所有节点的哈希都已是最新状态,rootHash变量此时已是最终的默克尔根。 -
检查空提交:
if hashedNode, dirty := t.root.cache(); !dirty是一项重要的优化。它检查根节点本身是否是脏的。如果根节点的状态未变,意味着整个Trie没有任何需要持久化的修改(例如,可能只进行了一些读操作)。在这种情况下,Commit过程可以提前结束,避免不必要的工作。 -
创建
NodeSet收集变更: 若Trie确实发生了变更,代码会创建一个trienode.NewNodeSet对象。它的作用类似于一个“数据集”,用于收集所有被修改或删除的节点信息,为最终写入数据库做准备。 -
委托给
committer执行:Commit函数本身并不直接执行繁重的节点收集工作,而是将任务委托给一个临时的committer对象。t.root = newCommitter(...).Commit(t.root, ...)这一行是整个过程的核心,它启动了实际的提交过程。这是一种将复杂逻辑模块化的清晰设计。 -
committer的工作:committer会最后一次遍历Trie,收集所有脏节点的RLP编码数据,并将它们添加到NodeSet中。这个NodeSet就是最终要交给数据库层进行写入的完整产物。为了提高性能,当变更数量较多时(t.uncommitted > 100),committer甚至可以并行处理此过程。 -
收尾: 当
committer完成工作后,内存中的Trie状态被标记为“已提交”(t.committed = true),uncommitted计数器被清零。函数最后返回计算出的根哈希和包含所有待写入数据的NodeSet。
当整个过程递归回到根节点并完成哈希计算后,我们就得到了最终的Merkle Root。这个根哈希是对整个Trie当前所有键值对的一个简短、安全、可验证的加密承诺。任何对Trie内容的微小改动,都会导致根哈希发生巨大变化。
func (t *Trie) Commit(collectLeaf bool) (common.Hash, *trienode.NodeSet) {
defer func() {
t.committed = true
}()
// Trie is empty and can be classified into two types of situations:
// (a) The trie was empty and no update happens => return nil
// (b) The trie was non-empty and all nodes are dropped => return
// the node set includes all deleted nodes
if t.root == nil {
paths := t.deletedNodes()
if len(paths) == 0 {
return types.EmptyRootHash, nil // case (a)
}
nodes := trienode.NewNodeSet(t.owner)
for _, path := range paths {
nodes.AddNode(path, trienode.NewDeletedWithPrev(t.prevalueTracer.Get(path)))
}
return types.EmptyRootHash, nodes // case (b)
}
// Derive the hash for all dirty nodes first. We hold the assumption
// in the following procedure that all nodes are hashed.
rootHash := t.Hash()
// Do a quick check if we really need to commit. This can happen e.g.
// if we load a trie for reading storage values, but don't write to it.
if hashedNode, dirty := t.root.cache(); !dirty {
// Replace the root node with the origin hash in order to
// ensure all resolved nodes are dropped after the commit.
t.root = hashedNode
return rootHash, nil
}
nodes := trienode.NewNodeSet(t.owner)
for _, path := range t.deletedNodes() {
nodes.AddNode(path, trienode.NewDeletedWithPrev(t.prevalueTracer.Get(path)))
}
// If the number of changes is below 100, we let one thread handle it
t.root = newCommitter(nodes, t.prevalueTracer, collectLeaf).Commit(t.root, t.uncommitted > 100)
t.uncommitted = 0
return rootHash, nodes
}