论文阅读《基于强化学习的协同公式化Alpha因子集合生成方法》
0. 论文基本信息
- 标题:Generating Synergistic Formulaic Alpha Collections via Reinforcement Learning
- 作者/机构:Shuo Yu, Hongyan Xue, Xiang Ao, Feiyang Pan, Jia He, Dandan Tu, Qing He(中国科学院计算技术研究所/中国科学院大学;华为EI创新实验室等)
- 发表出处/时间:KDD 2023(arXiv:2306.12964v1,2023-05-25)
1. 核心问题与创新总览
量化交易中常将历史价格/成交量等原始数据变换为可解释的市场信号,称为阿尔法因子 (alpha factor)。其中,公式化阿尔法 (formulaic alpha) 因可解释性强而常用于风控敏感场景;然而,实践中通常并非单因子使用,而是将多个因子输入下游组合模型以提升预测精度。传统自动挖掘方法大多“逐个”生成因子,并用互信息系数或互相关等相似性指标筛选“多样性”,忽略了因子最终将被组合这一事实,导致得到的因子集合在组合后增益有限,甚至与筛选指标不一致。
本文提出一种以“协同公式化阿尔法集合 (synergistic formulaic alpha set)”为直接目标的挖掘框架:不再用单因子表现或互相关过滤来间接追求协同,而是直接以下游组合模型的整体表现作为强化学习回报,驱动生成器持续产生“能提升当前因子池组合性能”的新因子;同时利用强化学习 (reinforcement learning, RL) 在巨大公式搜索空间中的探索能力,通过策略梯度 (policy gradient) 方法(实现采用近端策略优化 (Proximal Policy Optimization, PPO))训练序列生成器,逐步改良因子池,使生成的因子在组合意义上更具协同。
2. 背景与研究动机
在该工作之前,阿尔法挖掘大体分为两类路线:其一是基于机器学习的端到端预测模型(例如LSTM、Transformer或融合事件/图结构信息的模型),通常表达力强但可解释性相对不足,且可能依赖非价格/量数据;其二是公式化阿尔法,传统由人工专家构造,或由遗传编程 (genetic programming, GP) 等自动方法在算子-特征空间中搜索,具备较强可解释性。
现有公式化自动生成方法的关键局限在于:
- 单因子目标偏置:多数方法以单个因子的预测能力(如信息系数 (information coefficient, IC))为适应度/回报,得到的因子未必能在组合后带来额外增益。
- 相似性过滤不等价于协同:常用互IC/互相关阈值筛选“去冗余”,但本文指出:即便两个因子互IC很高,线性组合仍可能形成新的方向,带来显著增益;反之互IC较低也不必然协同。
- 搜索空间巨大与效率问题:GP维护大规模种群并进行变异/交叉,扩展性与效率受限;而“直接搜索一个因子集合”会让空间进一步爆炸,传统框架难以承受。
基于上述观察,作者将“协同集合”作为研究对象,并以“组合模型性能”作为真正与应用一致的优化信号,从而避免用互IC等代理指标造成目标错位。
3. 方法论深度解构 (Methodology)
3.1 整体架构与工作流
框架由两个核心部件组成:
- 阿尔法组合模型 (Alpha Combination Model):维护一个规模受控的因子池,并学习因子权重,将多个公式化因子组合为一个“巨型因子”。
- 基于强化学习的阿尔法生成器 (RL-based Alpha Generator):以序列方式生成公式表达式;每生成一个新因子,就将其加入因子池并重新优化组合权重;组合模型在数据上的表现作为回报,反向训练生成策略。
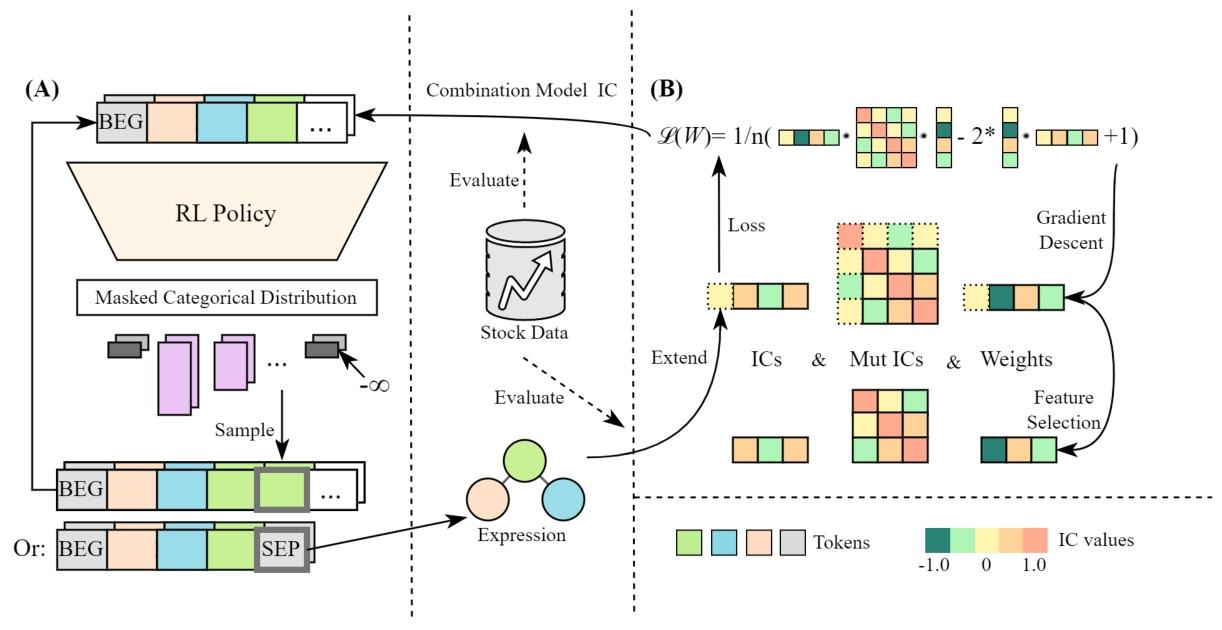
该流程对应论文中的迭代式“挖掘—组合—评价—更新”:生成器持续探索新公式;组合器以增量方式维护主因子集合;二者共同推进协同集合的形成。
3.2 问题定义与度量:从单因子到集合优化
3.2.1 数据与阿尔法形式化
设市场中有 只股票、共 个交易日。第 天第 只股票的输入特征向量为 (由 个原始特征在最近 天展开组成)。将某一天所有股票特征堆叠为 。 阿尔法因子 (alpha factor) 定义为函数
其中 是当天对所有股票的因子取值向量。
3.2.2 信息系数与平均IC
给定目标收益/趋势向量 ,定义日度信息系数 (information coefficient, IC) 为皮尔逊相关:
跨天平均记为 。 单因子与目标的平均IC:
3.2.3 组合模型目标
将一组因子 输入组合模型 (参数 ),希望在训练数据上最大化组合IC:
因此“挖掘协同集合”可写为对集合的优化:寻找使 最优的 。
3.3 公式化阿尔法表示:表达式树与逆波兰表示
公式化阿尔法由算子与原始特征组成,可自然表示为表达式树;为便于自回归生成,本文使用逆波兰表示 (Reverse Polish Notation, RPN) ——即表达式树的后序遍历序列,算子元数固定使其表示无歧义。
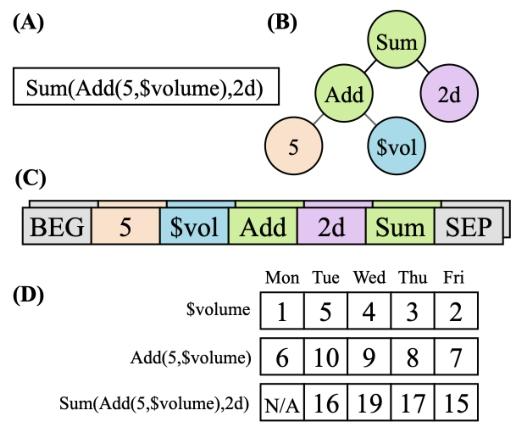
这一表示使“生成一个公式”转化为“生成一个token序列”,并允许通过栈规则判断RPN是否形成合法表达式。
3.4 阿尔法组合模型:线性“巨型因子”与高效损失计算
3.4.1 归一化与线性组合
不同因子尺度差异大,直接组合会影响优化稳定性。本文对每个交易日的截面向量执行中心化与归一化,使均值为0、向量长度为1。定义归一化算子 :
后续默认 与 均已归一化。
线性组合模型(保持可解释性):
3.4.2 以MSE训练,但用相关结构重写损失
定义均方误差 (Mean Squared Error, MSE):
关键结论(定理3.1):在归一化前提下, 可仅由“因子-目标IC”与“因子-因子互相关”表达:
直觉解释:归一化后,皮尔逊相关等于内积,因此 展开后可写成 的自内积(由互相关给出)减去与 的内积(由IC给出)加常数项。这样在权重梯度下降时无需反复显式构造 ,只需缓存/计算 与 ,显著降低每步计算负担。
3.4.3 因子池规模控制:增量加入+“剔除最小权重”
组合所有已生成因子需要 的互相关计算, 大时昂贵。本文认为几十个因子足够实用且存在边际收益递减,因此设置池容量上限:每生成新因子先加入并随机初始化权重,然后梯度下降优化 ;若超出阈值则移除绝对权重最小的因子(保留“主因子”)。
对应的增量优化伪代码要点:
- 将新因子 加入 ;
- 计算/缓存每个 的 ;
- 计算/缓存任意对 的 ;
- 迭代若干步对 做梯度下降;
- 找到 ,从集合中移除 及其权重。
3.5 阿尔法生成器:将公式生成建模为MDP并用PPO训练
3.5.1 Token设计
生成的最小单位为token,覆盖四类:
- 算子 (operators):截面算子与时序算子(如加减乘除、、、等);
- 特征 (features):如 ;
- 常数 (constants):离散常量集合(如 );
- 时间跨度 (time deltas):如 ; 并引入序列标记 BEG(begin) 与 SEP(end of expression)。
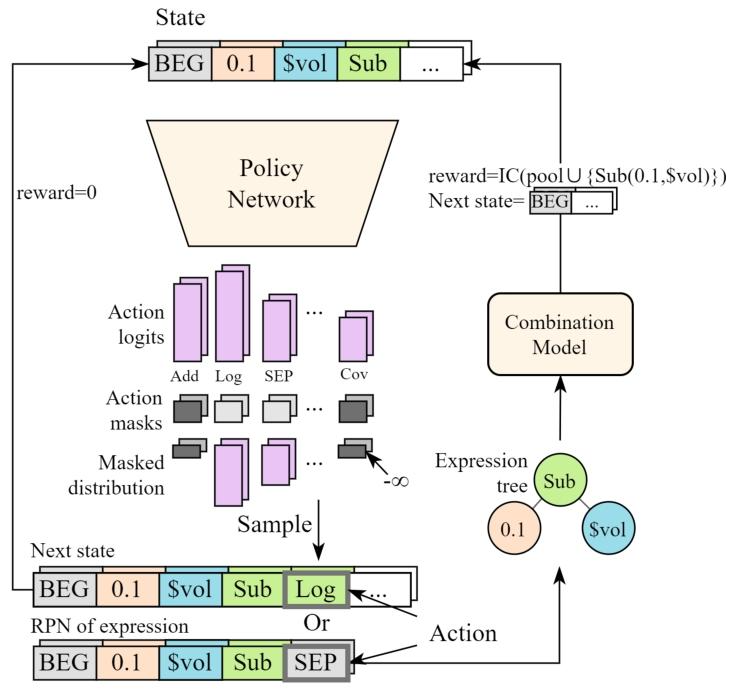
3.5.2 MDP要素
- 状态空间 (state space):状态 为当前已生成token序列(以 BEG 开始)。为保证可解释性,序列长度上限设为20。
- 动作空间 (action space):动作 为下一token。但任意token序列不一定是合法RPN,因此每个状态只允许满足合法性约束的token作为可选动作。
- 转移 (dynamics):确定性转移 。
- 回报与奖励 (rewards/returns):中间步骤奖励为0;当生成结束(输出SEP或达到长度上限)且表达式可解析时,将新因子加入组合模型并优化权重,然后用新组合的平均IC作为该episode回报。折扣因子设 ,不惩罚更长表达式。
该回报设计的核心含义是:生成器只因“对当前因子池的组合性能带来提升”而获得高回报,从目标层面强制对齐“协同集合”而非“单因子最强”或“互相关最小”。
3.5.3 合法性保证:形式合法与语义合法
生成RPN时使用“栈”规则进行形式合法性约束,典型规则包括:
- 时序算子必须以时间跨度token作为最后一个参数;
- 算子必须按元数消耗足够的操作数(截面/时序一元、二元);
- 多token表达式不得退化为常数;
- SEP 仅在当前序列已构成合法RPN时允许。
语义合法性处理:某些形式正确的表达式仍可能不可计算(如 作用于非正值)。此类表达式在实验中被赋予回报 (皮尔逊相关的最小值)以抑制生成。
3.5.4 PPO目标函数与Invalid Action Masking
PPO采用截断目标:
其中
为优势函数估计, 为截断范围。 由于动作空间受复杂合法性约束,本文采用无效动作掩码 (Invalid Action Masking) 将非法动作概率置零,仅在合法动作集合上采样,避免策略网络频繁采到无效token导致训练崩溃。
3.5.5 网络结构
策略网络与价值网络共享一个基于LSTM (Long Short-Term Memory, LSTM) 的序列特征提取器:2层、隐藏维128、dropout 0.1;其后分别接两层隐藏维64的MLP头。PPO截断范围 。
3.5.6 端到端挖掘流水线
整体伪代码(对应论文Algorithm 2)要点:
- 初始化因子池 与权重 ;初始化策略 与经验缓冲;
- 环境步:采样token并追加;若结束则解析得到新因子 ,用增量组合优化更新 ;
- 计算新组合的IC作为回报 (否则为0);
- 用采样到的轨迹批量更新PPO参数;
- 反复迭代直至得到最终因子子集与权重。
3.6 算子集合:截面与时序四类
本文算子分为:截面算子 (cross-section operators) 与时序算子 (time-series operators),且各自分一元/二元:
- 截面一元:、
- 截面二元:、、
- 时序一元:、、、、、、、、、
- 时序二元:、
这些算子与离散常数、时间跨度token共同定义了可搜索的公式空间。
4. 实验设置与结果分析
4.1 实验环境
4.1.1 数据集与任务
实验使用中国A股市场数据,股票集合为沪深300 (CSI300) 与中证500 (CSI500) 成分股。输入原始特征共6个:。 预测目标为20日收益率(以收盘价买卖):
时间划分:训练集 2009/01/01–2018/12/31;验证集 2019/01/01–2019/12/31;测试集 2020/01/01–2021/12/31。
4.1.2 对比方法
-
GP:遗传编程 (genetic programming, GP),以单因子IC为适应度生成表达式树。
-
PPO:同一表达式生成器与PPO算法,但回报为单因子IC(非组合IC)。
-
集合构造策略:对上述“单因子生成器”产出的因子序列,再构造集合并用相同线性组合器评估:
- top:选训练IC最高的top-;
- filter:在top-基础上约束任意因子对互IC不超过0.7。
-
端到端机器学习基线(Qlib):XGBoost、LightGBM、MLP(输入为60天原始特征,直接预测20日收益)。
含随机性的组合设置均以10个随机种子重复。
4.1.3 评价指标
- IC:皮尔逊相关(同上定义)。
- 秩IC (Rank IC):将向量做秩变换 后再计算IC:
两者均“越大越好”。
4.2 主实验结果
4.2.1 与各类方法总体对比(CSI300/CSI500)
关键结果见论文表2(均值/标准差基于10次运行;带“*”者在池容量 中取最优)。总体结论是:本文方法在CSI300与CSI500上均取得最高IC与Rank IC,显著优于公式化生成基线与端到端ML模型。
实验结果对比表(KDD ‘23)
| Method | CSI 300 IC (↑) | CSI 300 Rank IC (↑) | CSI 500 IC (↑) | CSI 500 Rank IC (↑) |
|---|---|---|---|---|
| MLP | 0.0250 (0.0068) | 0.0401 (0.0081) | 0.0188 (0.0018) | 0.0458 (0.0045) |
| XGBoost | 0.0404 (0.0000) | 0.0576 (0.0000) | 0.0353 (0.0000) | 0.0639 (0.0000) |
| LightGBM | 0.0259 (0.0000) | 0.0324 (0.0000) | 0.0332 (0.0000) | 0.0609 (0.0000) |
| PPOtop* | -0.0166 (0.0028) | -0.0144 (0.0075) | 0.0025 (0.0076) | 0.0295 (0.0135) |
| GPtop* | 0.0078 (0.0218) | 0.0157 (0.0271) | 0.0200 (0.0112) | 0.0504 (0.0160) |
| PPOfilter* | -0.0044 (0.0107) | 0.0101 (0.0107) | 0.0042 (0.0042) | 0.0506 (0.0052) |
| GPfilter* | 0.0183 (0.0190) | 0.0298 (0.0227) | 0.0117 (0.0083) | 0.0562 (0.0105) |
| Ours* | 0.0725 (0.0105) | 0.0806 (0.0106) | 0.0438 (0.0064) | 0.0727 (0.0112) |
表2:主结果表——列出MLP、XGBoost、LightGBM、PPO_top、GP_top、PPO_filter、GP_filter、Ours在CSI300与CSI500上的IC与Rank IC均值/方差;其中Ours在两市场两指标均为最高
从表中可直接读到的代表性数值(测试集):
- CSI300:Ours 的 IC=0.0725、Rank IC=0.0806(均显著高于XGBoost的IC=0.0404、Rank IC=0.0576,以及其他公式化基线)。
- CSI500:Ours 的 IC=0.0438、Rank IC=0.0727(同样为最高)。
作者进一步解释:仅以单因子IC训练的RL生成器容易陷入局部最优并在训练集过拟合,搜索停滞;GP虽能避免部分停滞,但仍难以在“组合协同”意义上持续产出增益因子;互IC过滤也无法稳定解决协同问题。
4.2.2 随因子池容量变化的可扩展性(Q2)
论文图4比较了不同池容量 下各公式化生成方案的组合表现。池容量为1表示只取最强单因子、不进行组合。
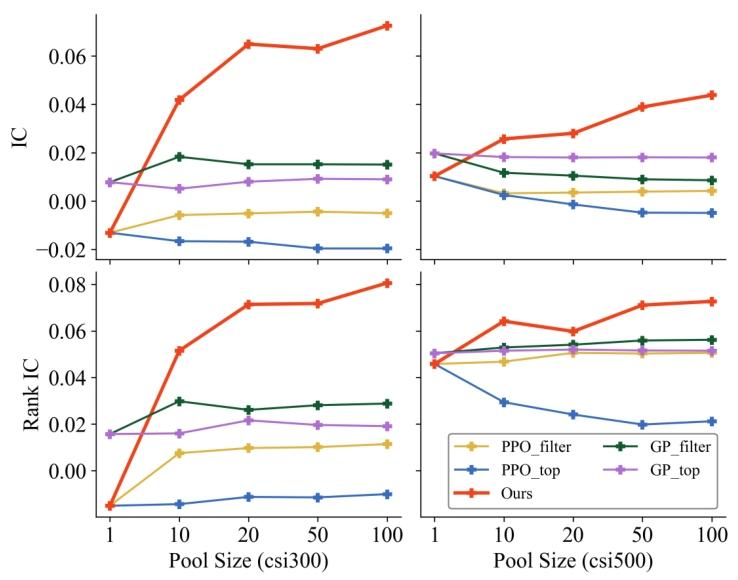
图4所体现的核心现象:
- 本文方法使用“组合模型IC”作为回报,随着池容量增加仍能不断找到能提升现有池的因子,表现持续提升,显示出协同挖掘的可扩展性。
- 其他方法的“组合表现”随池容量增大提升有限,甚至接近“只用top alpha”的水平,说明其因子之间协同弱。
- CSI500上GP_filter在IC指标随池容量增大变差,直接展示了互IC过滤并不等价于组合性能提升(Q3的一部分证据)。
4.3 案例分析:高互IC也可能强协同(Q3)
论文表3给出一个由本文框架生成的10因子组合示例(CSI300),并列出每个因子的权重与单因子IC,以及最终加权组合IC=0.0511。值得注意的是:该集合中许多因子对的互IC超过0.7,按以往工作常被认为“过于相似”,但在组合中仍能协同提升。
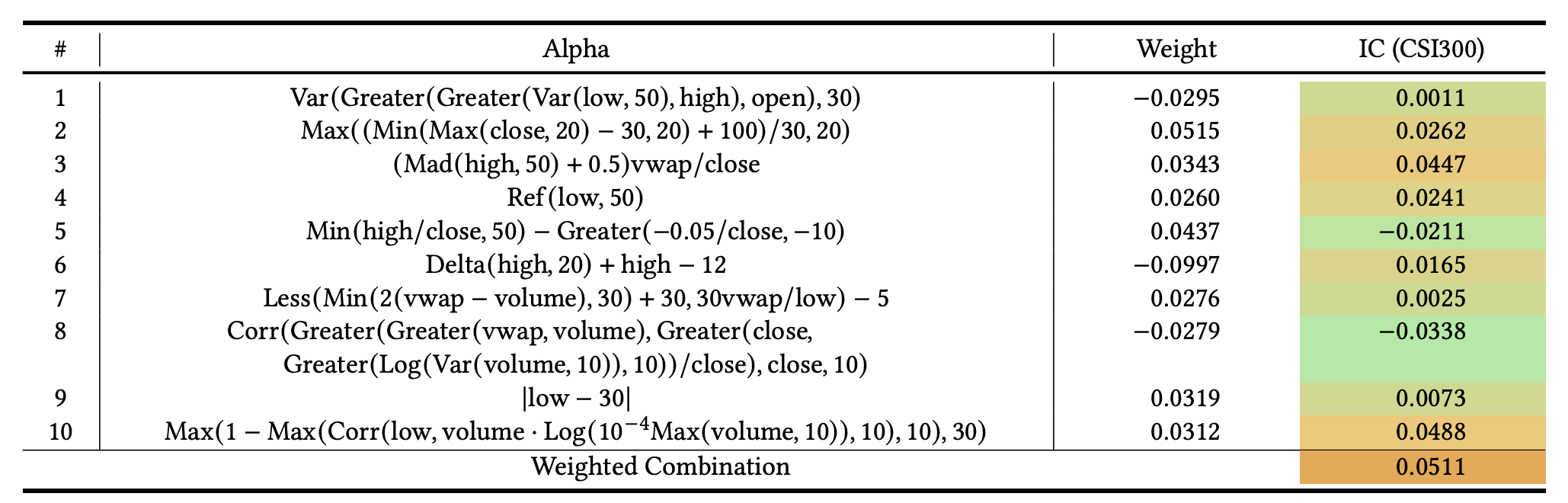
作者给出的两个关键观察:
- 两个互IC极高的因子(示例中#2与#6互IC为0.9746)线性组合后在测试集取得IC=0.0458,甚至高于两者单因子IC之和,体现协同。
- 单因子IC几乎为0的因子(示例#1 IC=0.0011)在组合中仍“关键”:移除该因子并重新训练权重后,组合IC下降到0.0447。
作者提出一种线性空间直觉解释:当两个向量非常接近时,它们的差向量趋近于与原向量正交,从而线性组合可能指向新的方向;因此“互IC高”并不必然意味着“组合无增益”。
4.4 更贴近交易的投资回测(Q4)
在CSI300测试期(2020/01/01–2021/12/31)进行回测。采用简单的 top-/drop- 策略:每天按alpha值排序选前 只股票等权持有,并限制每天最多买卖 只以降低交易成本。实验设定 。记录各方法净值曲线,论文图5显示本文方法获得最高累计收益。
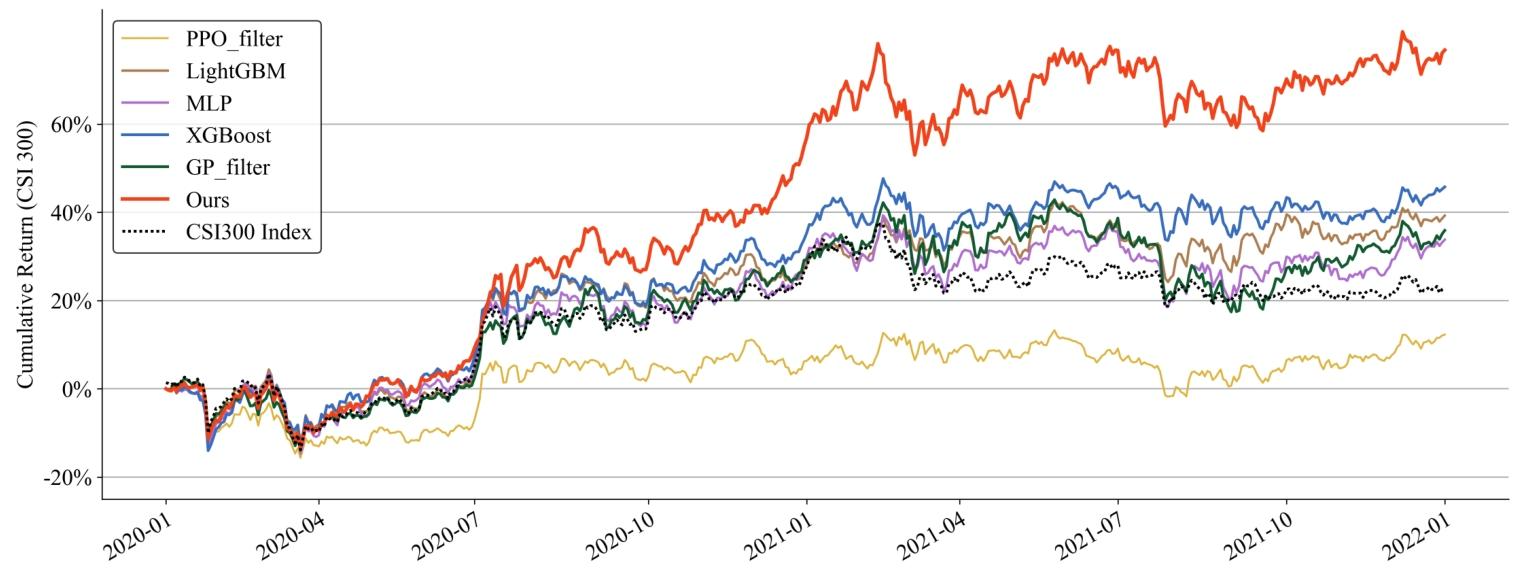
作者强调:尽管训练目标是预测相关性(IC)而非直接收益最大化,生成的协同因子集合仍在该回测策略下表现最好。
5. 结论与展望
作者总结指出:本文提出了一个面向可解释公式化因子的挖掘框架,通过将“新因子加入后对现有组合带来的性能提升”作为协同度量与强化学习回报,使得生成器能够直接面向下游组合任务优化,产出可协同工作的因子集合;同时将公式生成过程建模为马尔可夫决策过程 (Markov Decision Process, MDP),并使用强化学习方法提升在巨大公式空间中的探索效率。大量实验表明,该框架在预测指标(IC、Rank IC)与更贴近交易的回测中均优于以往公式化因子挖掘方法,并能在更现实的设置下保持优势。