翻译《如何像对冲基金一样使用预测市场数据(完整路线图)》
以下是经过专业校对的完整翻译:
如何像对冲基金一样使用预测市场数据(完整路线图)
我将详细拆解对冲基金如何利用预测市场数据构建交易策略,并提取散户错过的 Alpha(超额收益)。此外,我还将分享一个包含 4 亿多笔交易、追溯至 2020 年的数据集。
我们直接开始。
收藏本帖 我是 Roan,一名后端开发者,专注于系统设计、高频交易(HFT)风格的执行以及量化交易系统。我的工作重点是预测市场在负载下的实际表现。如有任何建议、深思熟虑的合作或伙伴关系,欢迎私信。
刚刚公开的数据集
Jon Becker (@beckerrjon) 发布了最大的公开可用预测市场数据集:包含来自 Polymarket 和 Kalshi 的 4 亿多笔交易,数据追溯至 2020 年。包含完整的市场元数据、细粒度交易数据、结算结果,存储为 Parquet 文件。
这是 Tick 级(逐笔) 数据。每笔交易都有时间戳、价格、成交量、吃单方向(taker direction)。这种颗粒度的数据在传统市场中,机构数据供应商每年的收费超过 10 万美元。
现在它是开源的。这意义重大。
在我拆解对冲基金如何利用这些数据之前,让我展示如何实际设置它。因为与大多数只谈理论的文章不同,我将为你提供访问机构级数据的确切步骤。
如何设置数据集(分步指南)
前提条件:
- 安装 Python 3.9 或更高版本
- 40GB 可用磁盘空间
- 命令行访问权限(Mac/Linux 上的 Terminal,Windows 上的 PowerShell)
第一步:安装 uv(依赖管理器)
# 在 Mac/Linux 上
curl -LsSf https://astral.sh/uv/install.sh | sh
# 在 Windows (PowerShell) 上
irm https://astral.sh/uv/install.ps1 | iex第二步:克隆仓库
git clone https://github.com/Jon-Becker/prediction-market-analysis
cd prediction-market-analysis第三步:安装依赖
uv sync这将安装 DuckDB、Pandas、Matplotlib 和其他分析工具。
第四步:下载数据集
make setup这将从 Cloudflare R2 下载 data.tar.zst(压缩后 36GB)并将其解压到 data/ 目录。
解压过程根据系统不同需要 5 到 30 分钟(对我来说比预期的要长)。
第五步:验证数据
ls data/polymarket/trades/
ls data/kalshi/trades/你应该能看到数百个包含交易数据的 Parquet 文件。 恭喜。你现在拥有对冲基金正在分析的相同数据集。
数据的组织结构如下:
data/
├── polymarket/
│ ├── markets/ # 市场元数据(标题、结果、状态)
│ └── trades/ # 每笔交易(价格、成交量、时间戳)
└── kalshi/
├── markets/ # Kalshi 的相同结构
└── trades/每个交易文件都是一个 Parquet 文件。什么是 Parquet 文件? Parquet 是一种列式存储格式,允许你查询数十亿行数据而无需将所有内容加载到内存中。
现在你已经设置好了,让我展示机构实际上是如何利用这些数据的。
对冲基金实际上如何使用这些数据
你以为预测市场是用来赌结果的。 你错了。
对冲基金将预测市场数据作为实验室,用于三件事:实证风险校准、系统性偏差检测和订单流分析。预测市场不是他们部署资本的地方,而是他们提取模式的地方,这些模式为传统市场中数十亿美元的头寸提供信息。
以下是他们如何利用这 4 亿笔交易的具体做法。
方法 1:带有蒙特卡洛不确定性量化的实证凯利公式
凯利公式是量化仓位管理(Position Sizing)的基础。 每个机构交易员都知道这个公式:
其中 是部署资本的最佳比例, 是获胜概率, 是失败概率, 代表赔率。
教科书式凯利公式的问题在于:它假设你确切地知道自己的优势(Edge)。 现实立刻打破了这个假设。
当你的模型估计某笔交易有 6% 的优势时,那不是事实真相。那是一个带有不确定性的点估计。真实优势可能是 3%,也可能是 9%。你拥有的是一个分布,而不是一个数字。
标准凯利公式将那 6% 视为事实。这在数学上是不正确的,会导致系统性过度下注。
实证凯利(Empirical Kelly)通过将不确定性直接纳入仓位计算来解决这个问题。
以下是他们使用 Becker 数据集实现它的方法:
第一阶段:历史交易提取
基金用精确的术语定义他们的策略标准。 例如:“当合约价格低于 0.15 美元且我们的基本面模型估计真实概率高于 0.25 时,买入 Yes。”
他们过滤 4 亿笔历史交易,找到该确切模式出现的每一次实例。不是相似,是确切。 这给了他们数千个历史类比。每一个都有已知的结果,因为数据集包含结算信息。
第二阶段:回报分布构建
针对每一段历史相似行情,他们会计算其实际实现收益:盈利还是亏损、幅度大小、发生时点。由此构建出经验收益分布—— 并非理论上的正态分布,而是该形态在真实市场中出现时,实际发生的收益分布。
关键洞察: 这个分布几乎从来不是正态的。它有肥尾。它有偏度。它的峰度会让统计学教授皱眉。 传统模型假设这些特征不存在。实证方法直接测量它们。
第三阶段:蒙特卡洛重采样
这里数学变得有趣了。 历史回报序列只是众多可能路径中的一种。 如果相同的交易以不同的顺序发生,权益曲线看起来会完全不同。
回报为 [+8%, -4%, +6%, -3%, +7%] 的平均值与 [-4%, -3%, +6%, +7%, +8%] 相同,但回撤 profile 截然不同。第一个序列从未低于 0%。第二个序列立即触及 -7% 的回撤。
这就是路径依赖性。这对风险管理至关重要。
蒙特卡洛重采样通过对同一组历史收益率进行随机重排,生成 10,000 条备选路径。每条路径的统计特征完全一致,但实际风险表现各不相同。
第四阶段:回撤分布分析
为10,000条模拟路径分别计算最大回撤,即从峰值到谷值的最严重跌幅。
由此你将得到一组可能的最大回撤分布,而非单一数值。你可以查看其中位数(50%分位,中性情形)、95%分位(不利情形)与99%分位(极端灾难情形)。
这就是机构风险管理与散户分道扬镳的地方。
- 你: “回测显示最大回撤12%,我能承受。”
- 机构: “中位路径回撤为12%,但95分位回撤达31%。我们应按95分位水平配置仓位,而非中位水平。”
第五阶段:不确定性调整后的仓位 sizing
最后一步是计算仓位规模,确保95分位回撤控制在机构风险限额以内。
数学变为:
其中 是蒙特卡洛模拟中边缘估计的变异系数(标准差 / 均值)。
- 高不确定性 → 大 CV → 大幅削减仓位大小。
- 不确定性低 → 变异系数小 → 仓位规模更接近理论凯利值。
举例说明:
量化策略:买入价格低于 0.20 且模型预估真实胜率大于 0.30 的合约。
基于 Becker 数据集的历史模式匹配与蒙特卡洛重采样测算:
- 标准凯利计算建议仓位:20% 以上
- 经波动率调整后仓位:约 15%–20%
- 经蒙特卡洛不确定性调整后(典型变异系数 CV:0.3–0.5):10%–15%
- 考虑模型风险后的保守执行仓位:8%–12%
忽视不确定性(仓位超20%)与纳入不确定性(仓位10%)之间的差异,本质上是大概率爆仓与长期稳健复利的区别。
为什么这很重要
所有使用凯利公式的个人交易者,采用的都是教科书版本。
他们会系统性地下注过重,原因在于未考量优势估计值中的不确定性。
而运用经验凯利结合蒙特卡洛模拟的机构投资者,则是针对可能结果的分布来确定仓位规模,而非单点估计。
久而久之,两者会产生巨大分化。个人交易者遭遇40%最大回撤,数年收益付诸东流;机构投资者回撤从未超过20%,实现平稳复利增长。
同样的策略,只因仓位管理方法不同,结果却天差地别。
方法 2:跨价格和时间维度的校准表面分析
标准校准分析会绘制隐含概率与实际发生频率的对比曲线。
当价格为0.30美元(隐含概率30%)时,该事件实际发生的频率是多少?若实际发生概率为30%,说明市场定价校准准确;若为25%,则定价偏高;若为35%,则定价偏低。
这是单维度分析,仅考虑价格因素。
机构则会构建校准曲面,加入时间维度:随着到期日临近,校准效果会如何变化?
框架
定义 为校准函数,其中:
- 代表合约价格(0 到 100)
- 代表距离结算的剩余时间(以天为单位)
- 返回结果发生的实证概率
在完美校准的市场中,对于所有 和 ,。 实际上, 随价格和时间系统性地变化。
Jon Becker 的研究实际显示了什么
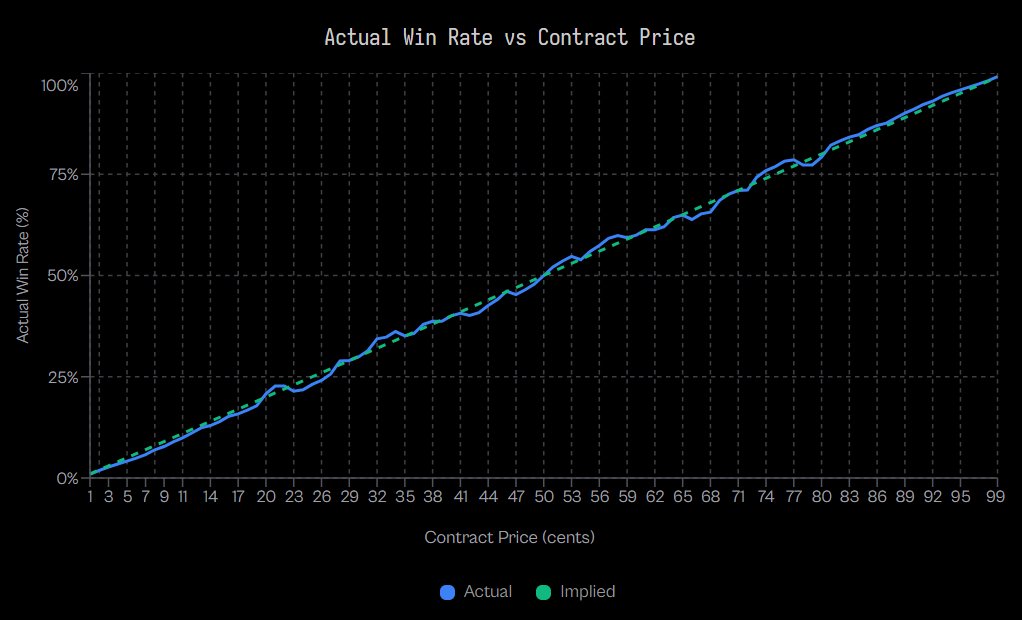
通过对7210万笔Kalshi交易的分析证实,小概率高估偏差真实存在且可量化。
在极低概率区间(1美分合约):
- Taker 胜率仅为 0.43%
- 隐含概率:1%
- 定价偏差:-57%(表现远低于预期)
在中等概率区间(50美分合约):
- Taker 定价偏差:-2.65%
- Maker 定价偏差:+2.66%
- 偏差依然存在,但幅度已大幅收窄。
研究证实,在99个价格区间中,Taker有80个区间呈现超额收益为负的情况,这表明全概率区间均存在系统性定价偏差。
机构关于时间维度的假设
尽管 Becker 已发表的研究侧重于基于价格的校准(Price-based Calibration),但机构基于行为金融学理论,将这一框架延伸到了时间维度。
核心假设: 冷门偏差(Longshot Bias)应随距离结算的剩余时间而变化,因为其背后的心理驱动因素会发生改变。
- 早期阶段(距离结算尚早): 散户情绪主导。信息有限。人们基于希望而非概率购买“彩票”。此时冷门偏差应达到峰值。
- 中期阶段: 信息逐渐积累。专业参与者入场。随着信息环境改善,价格应向基本面收敛。
- 晚期阶段(接近结算): 信息揭示加速。原本低概率的结果变得显然不可能。假设表明,随着希望破灭,可能会出现偏差反转,但这需要实证验证。
策略框架
基于既定行为模式的随时间变化的过滤规则:
- 距离结算尚早: Becker 记录的冷门偏差在此阶段可能最为显著。策略: 系统地做空由散户热情主导的低概率合约。
- 中期阶段: 随着信息和流动性改善,进入效率高峰期。策略: 减少交易活动或专注于其他边缘。
- 接近结算: 信息不对称应崩溃。策略: 利用任何剩余的定价错误,但需注意市场效率通常会提升。
数学形式化
定价错误函数:
其中 代表以百分点为单位的系统性定价错误。
机构入场规则将是:
- 当 时做空(定价过高)
- 当 时做多(定价过低)
- 当 时保持空仓(公平定价)
阈值需根据交易成本和所需的风险调整后回报进行校准。
为什么这很重要
Becker 的研究证明了**冷门偏差(Longshot Bias)**存在于价格维度。记录的 1 美分合约 -57% 定价错误是巨大且系统性的。
机构假设这种偏差随时间变化,尽管实证验证需要对完整时间数据集进行分析。
框架是合理的:由希望、恐惧和信息不对称驱动的行为偏差应逻辑地随结算临近而变化。
无论是“早期偏差 → 中期效率 → 晚期反转”的具体模式,还是其他时间结构,都需要在 4 亿笔交易数据集上运行分析来确定。
我们从验证研究中确切知道的是:
- 冷门偏差存在且可测量(1 美分时为 -57%)
- 它随概率谱变化
- 吃单者在 99 个价格水平中的 80 个系统性亏损
- 偏差创造了结构性机会
机构实证测试的是:
- 这种偏差如何随结算剩余时间变化
- 模式在不同市场类别中是否稳定
- 入场和退出的最佳阈值水平
- 经交易成本调整后的盈利能力
校准表面方法提供了框架。Becker 数据集提供了实验室。实证分析确定哪些具体模式存在且可交易。
方法 3:订单流分解与挂单者 vs 吃单者盈利能力
这是最隐蔽的 Alpha(超额收益),也是散户交易员从未考虑过的领域。
每笔交易都涉及两方:提供流动性的挂单者(Maker)和消耗流动性的吃单者(Taker)。
- 挂单者下达限价单。他们等待成交。
- 吃单者穿越买卖价差。他们为即时性付费。
Jon Becker 的数据集标记了每笔交易的吃单方向。这意味着你可以将交易群体分为挂单者和吃单者,并独立分析他们的盈利能力。
Becker 的研究实际揭示了什么
对 7210 万笔具有结算结果的 Kalshi 交易的分析显示了鲜明的不对称性。
在 1 美分合约(极端冷门)下:
- 吃单者获胜率仅为 0.43%
- 隐含概率:1%
- 吃单者定价错误:-57%
- 挂单者获胜率:1.57%
- 挂单者定价错误:+57%
在 50 美分合约下:
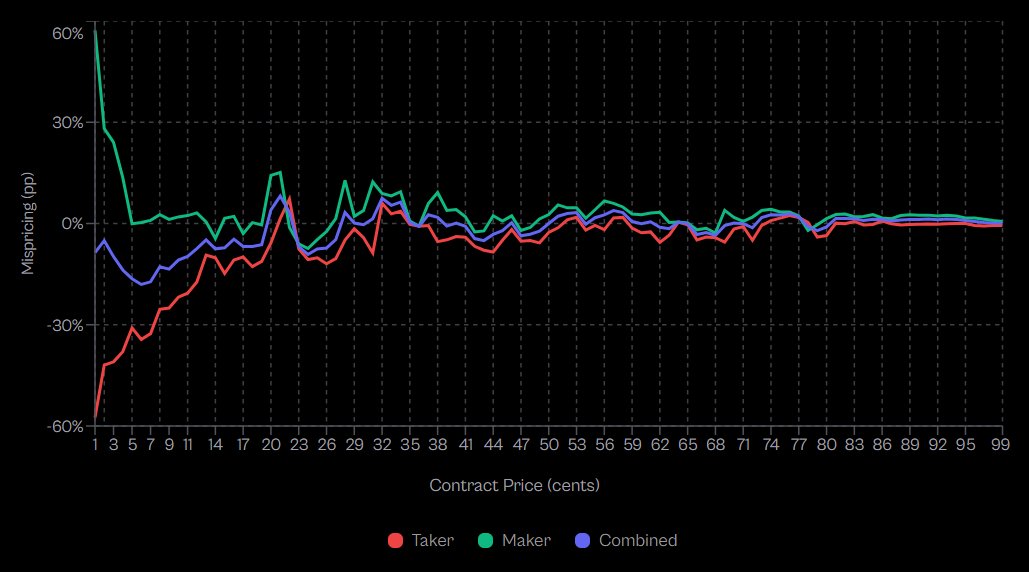
- 吃单者定价错误:-2.65%
- 挂单者定价错误:+2.66%
总体发现:
- 吃单者在 99 个价格水平中的 80 个表现出负超额回报
- 买入 YES 的挂单者:+0.77% 超额回报
- 买入 NO 的挂单者:+1.25% 超额回报
- 统计对称性(Cohen’s d ≈ 0.02)表明挂单者并非预测得更好,只是结构得更好
这不是微小的差异。
作为人群,吃单者系统性地错误。不是 50/50 猜硬币的错误。而是在 80% 的所有价格水平上持续、可测量的错误。
为什么吃单者亏损
Becker 的研究确定了核心见解:挂单者通过结构性套利获利,而非卓越的预测能力。
挂单者买入 YES(+0.77%)与买入 NO(+1.25%)的超额回报几乎相同,证明他们不是在挑选赢家。他们是在利用吃单者人群中的昂贵偏好。
吃单者行为揭示了紧迫性。你穿越价差是因为你重视执行确定性胜过价格。这种紧迫性与行为偏差相关。
- 信息不对称误解: 吃单者认为他们在根据有价值的信息行动。大多数不是。他们是在情绪化地对公共信息做出反应,而不是私下信息。
- 肯定性偏差: Becker 的研究显示,吃单者表现出“对肯定性、冷门结果的昂贵偏好”。他们不成比例地买入 YES 冷门,系统性地支付过高。
相反,挂单者展示了耐心。根据定义,他们等待。这种耐心过滤了情绪化紧迫性。
此外,挂单者优化的是价差捕获,而不是结果预测。随着时间的推移,价差收集加上相对于有偏差的吃单者流的结构性边缘产生了持续的正期望。
数学
每笔成交订单的预期挂单者利润:
其中:
spread_capture代表买卖价差收集edge_vs_takers代表实证胜率优势
来自 Becker 的验证数据:
- 挂单者相对于吃单者的边缘:根据仓位方向为 +0.77% 到 +1.25%
- 这种边缘存在于 99 个价格水平中的 80 个
- 边缘是结构性的,而非信息性的(由对称的 YES/NO 表现证明)
如果你在许多市场中一致地提供流动性,你就不需要卓越的预测能力也能反复获得这种边缘。
但也有风险。
- 库存风险: 作为挂单者,你积累仓位。你在某些市场做多,在其他市场做空。如果相关性转变或市场对你不利,在均值回归之前会发生回撤。
- 逆向选择风险: 并非所有吃单者都是不知情的。正如 Becker 指出的,“复杂的交易员穿越价差以根据时间敏感信息行动。”大订单可能信号知情流。你有被猎杀的风险。
- 成交量演变: Becker 的研究显示市场成熟度很重要。在早期的低成交量时期,即使是挂单者也输给相对知情的吃单者。成交量激增吸引了专业流动性提供者,他们随后可以在所有价格点提取价值。
机构做市框架
- 报价双向市场,具有正预期价差捕获。
- 允许代表散户吃单者流的小额成交(这些具有记录的偏差)。
- 标记大额成交以供审查(潜在的复杂参与者)。
- 监控 aggregate 库存 exposure,并在超过阈值时对冲。
- 目标是来自结构性边缘的一致回报,而不是结果预测。
为什么这很重要
散户交易员几乎总是吃单者。他们看到一个市场,点击买入,穿越价差。
通过这样做,他们进入了一个 Becker 的研究证明在 80% 的所有价格水平上具有负超额回报的人群。
在极端冷门(1 美分合约)下,吃单者表现不佳 57%。即使在中等概率(50 美分)下,他们也表现不佳 2.65%。
提供流动性的机构收集了该边缘的另一面。
相同的市场。不同的方法。由 7210 万笔交易证明的结构性优势。
研究结论
Becker 的分析表明,财富系统性地从流动性吃单者转移到流动性挂单者,这是由行为偏差和市场微观结构驱动的,而不是挂单者具有 superior 预测能力。
记录的吃单者对肯定性、冷门结果的偏好创造了结构性机会。挂单者的耐心和价差捕获方法收割了它。
这不是理论。这是来自有史以来分析过的最大预测市场数据集的测量、验证的现实。
机构边缘不是信息
这是散户对冲基金看法的错误之处。
他们假设对冲基金获胜是因为他们拥有更好的信息。更好的研究。更好的模型。更好的预测。
那不是边缘所在。
边缘在于:
- 风险管理: 为结果分布 sizing,而不是为点估计 sizing。蒙特卡洛不确定性调整防止破产。
- 时间变化策略: 利用随结算临近而变化的校准模式。卖出早期偏差。买入晚期反转。
- 结构性定位: 成为挂单者而不是吃单者。从不耐烦的交易对手那里收集价差和逆向选择边缘。
这些都不需要更好的预测。它们需要更好的流程。 Becker 数据集为你提供了构建该流程的实验室。
4 亿笔交易。每个结果已知。每个模式可测量。
散户将使用这些数据回测他们的预测。 机构将使用这些数据校准他们的风险管理,识别时间变化偏差并测量结构性边缘。