翻译《Polymarket 套利机器人构建指南》
Polymarket 套利机器人构建指南
你有没有注意到,交易机器人从 Polymarket 攫取了最大的利润?
现在每个散户都试图创建自己的机器人,但结果对每个人来说都一样:亏损。 原因很简单: 真正的机器人是由那些在构建之前刻苦研究过的人创建的。 单靠一份指南永远帮不了你。 Claude 这样的 AI 工具或 Rust 这样的编程语言也帮不了初学者。 这就是我创建这份指南的原因。
Polymarket 让用户对现实世界的事件进行投注。 价格反映了集体概率。
如果 YES 的交易价格为 $0.60,市场意味着有 的概率。
当定价打破这一逻辑时,套利就会发生。
在二元市场中,YES + NO 应该等于 $1。
但由于流动性缺口、执行延迟或关联条件,总和可能会偏离。
当这种情况发生时,就存在潜在的无风险利润。
示例: 如果 YES = $0.50 且 NO = $0.49,总计 $0.99。
这是定价错误(你以 $0.01 的折扣购买了 1 美元)。
套利机器人的存在就是为了自动捕捉这些低效机会。
但这并不是免费的钱,除非你理解其机制。
费用、滑点、Gas 成本和执行失败会迅速抹杀利润。
在构建任何东西之前,先研究为什么这些低效现象存在。
论文 《Arbitrage in Prediction Markets》 分析了真实的 Polymarket 数据。它显示了单一条件和多条件市场中 persistent 的套利机会。
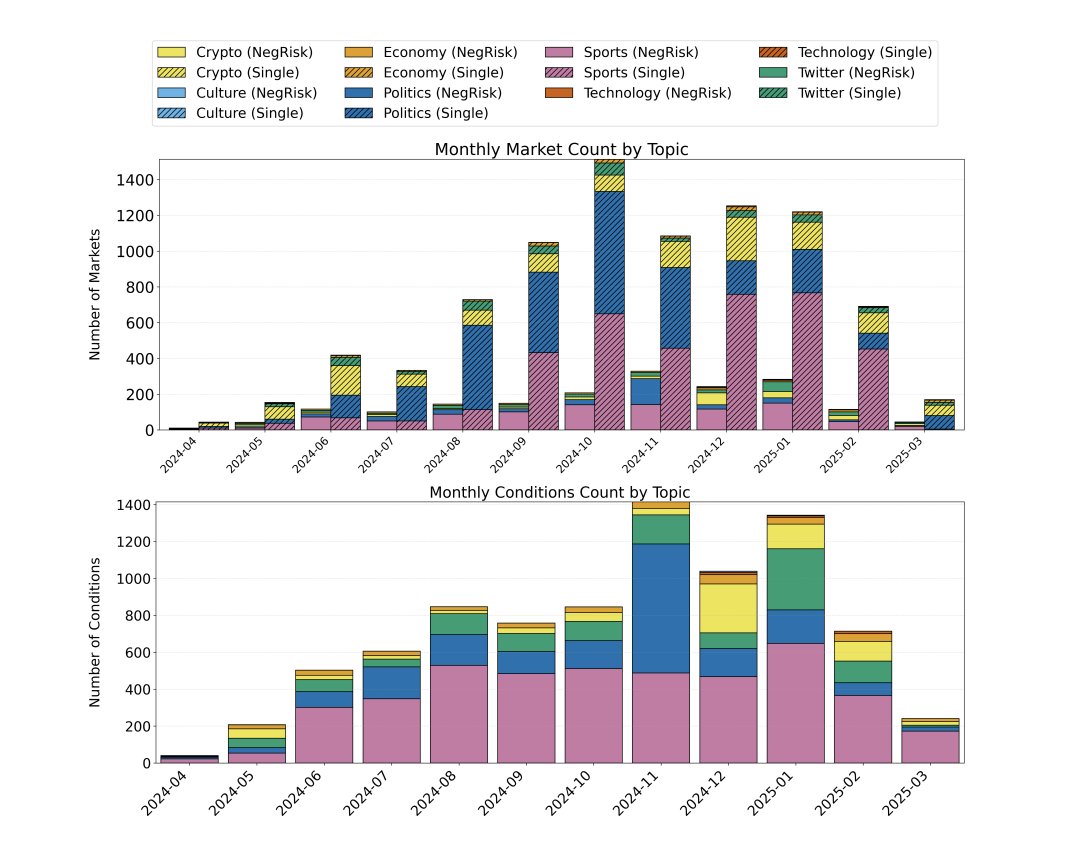
这些图表显示了按主题划分的交易量集中度,政治和体育占主导地位。 你自己检查一下: https://polymarket.com/event/fed-decision-in-march-885?via=bored2boar 截至目前交易量为 $1.45` 亿。
交易量越大 = 定价错误机会越多。
这些市场很混乱,因为信息流动不均匀且流动性碎片化。
为什么理论很重要?
因为有些套利并不明显。 市场看起来可能是独立的,但共享隐藏的语义重叠。
如果你的逻辑忽略了这一点,你的机器人会产生误报。
跨平台低效在 《Semantic Non-Fungibility》 论文中有涵盖。
它显示由于流动性碎片化,跨平台存在 的偏差。
如果你扫描多个场所,那是真正的超额收益 (alpha)。
对于组合市场,请阅读 《Arbitrage-Free Combinatorial Market Making》。
它解释了整数规划如何在事件树中保持定价一致。
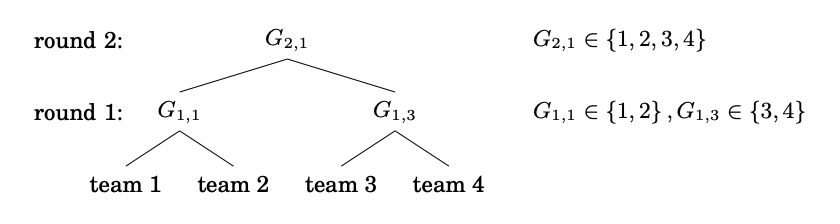
该方案可视化了锦标赛结构。 如果 A 队赢得半决赛,它必须出现在决赛中。
机器人必须理解这些依赖关系。
然后是自动化。
《Neural Networks for Static Arbitrage》 论文证明机器学习可以在没有预定义定价模型的情况下检测套利。
这对扩展至关重要。
你需要的工具:
- Python
- Web3.py
- Pandas
- NumPy
- SciPy
Polymarket API:
- 用于市场数据的 Gamma API
- 用于订单执行的 CLOB API
一切都是公开且免费使用的。 从理论开始,它可以防止愚蠢的错误。
Polymarket 上的核心套利概念
Polymarket 运行在 Polygon 上。
流动性来自自动做市商 (AMM)。
YES 和 NO 代币针对 USDC 进行交易。
主要有三种套利类型:
- 市场内套利 (Intra-market arbitrage)
- 市场间套利 (Inter-market arbitrage) 相关事件定价错误
- 跨平台套利 (Cross-platform arbitrage) 同一事件在其他地方定价不同
让我们分解它们。
单一条件套利
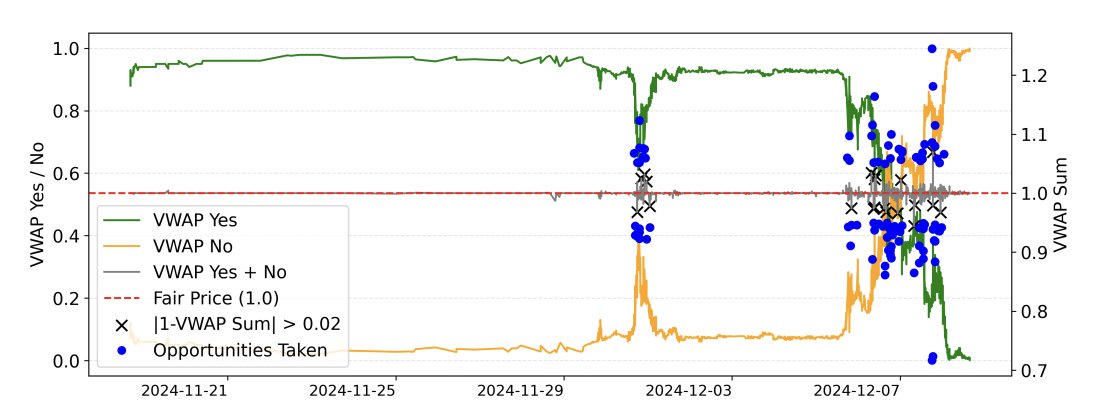
此图表显示了叙利亚市场中的成交量加权平均价 (VWAP) 价格偏差。
- 当偏差超过 时,机会出现。
这些缺口通常来自执行滞后。
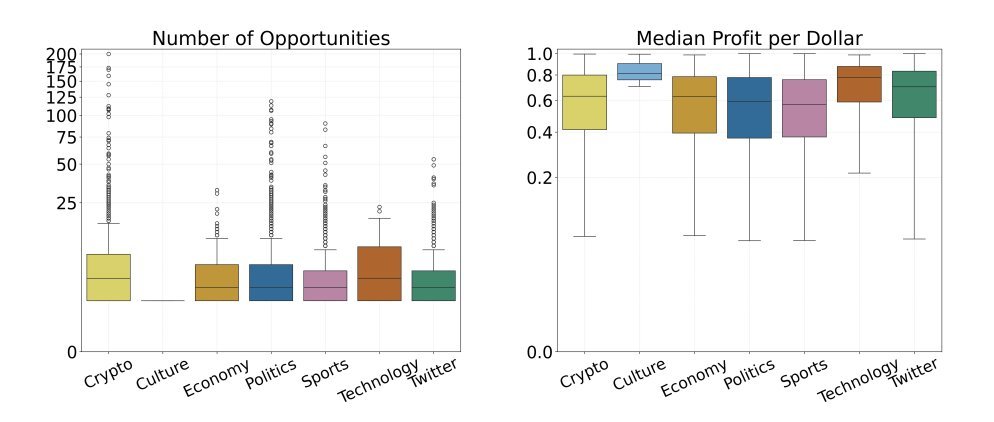
该方案显示中位数利润 >2 美分,尤其是在加密重度市场中。
微小的优势。高频。这就是游戏。
多条件套利
这些市场将结果捆绑在一起。
此图表证明政治主导了多条件套利。
流动性分布不均匀。 排名靠前的结果吸收了大部分交易量。
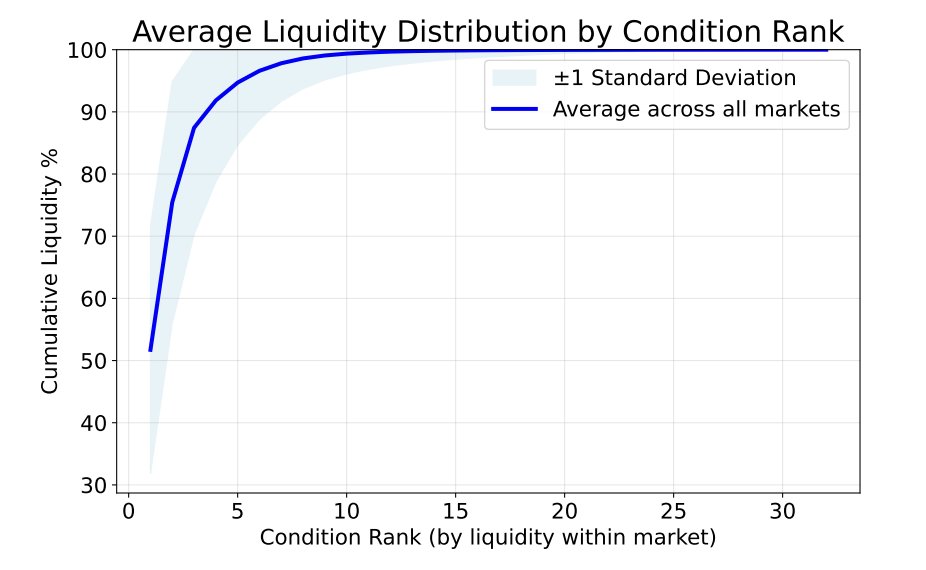
你的机器人应该优先考虑高流动性条件。
组合套利
使用整数规划在大型结果空间中强制执行无套利约束。
把它想象成解方程组。如果整个树的概率加起来不一致,就有优势。
语义套利
跨平台描述相似事件的市場可能漂移 。
示例: “候选人 X 会赢吗?”与“政党 Y 会赢吗?”
它们重叠。但市场将它们分开对待。
使用 NLP 对齐描述。这就是你检测语义相似性的方法。
机器学习检测
论文 “NEURAL NETWORKS CAN DETECT MODEL-FREE STATIC ARBITRAGE STRATEGIES” 在价格向量上训练神经网络。
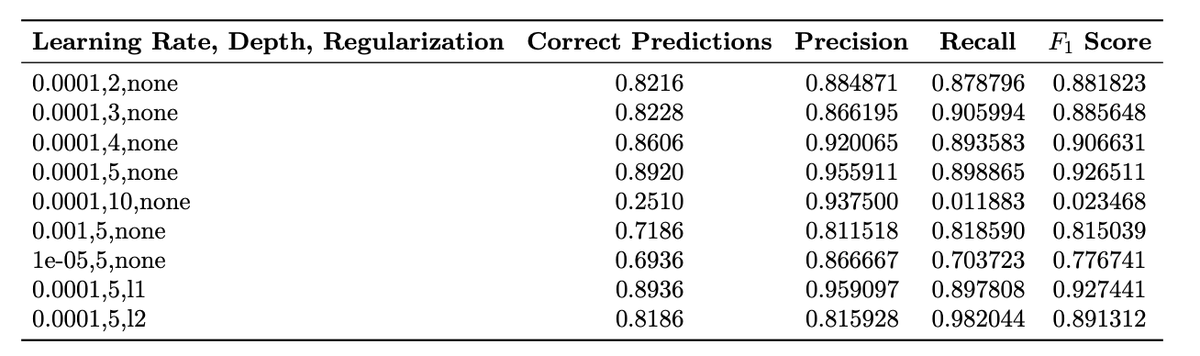
此表评估了精确率和召回率。
- 高维检测比硬编码规则扩展性更好。
为什么这一切很重要?
因为 Polygon 上的费用是 。 如果你的模型忽略了它们,你的“套利”就不是真实的。
从简单开始: 通过 REST API 获取价格。 检查 是否偏离阈值。
然后扩展。
设置你的环境
你需要干净的基础设施。
推荐栈:
- Python 3.12+
- requests
- web3.py
- pandas
- asyncio
- torch (用于 ML)
安装:
pip install web3 requests pandas torch
Polymarket API:
/markets用于列表/orders用于订单簿
对于历史数据,使用 The Graph 子图: (matic-markets via docs.bitquery.io)
为什么?
实时 API 检测当前的低效。 子图帮助你回测。
设置钱包:
- MetaMask
- Polygon 网络
- 注入 MATIC + USDC
测试连接:
from web3 import Web3
w3 = Web3(Web3.HTTPProvider('polygon-rpc.com'))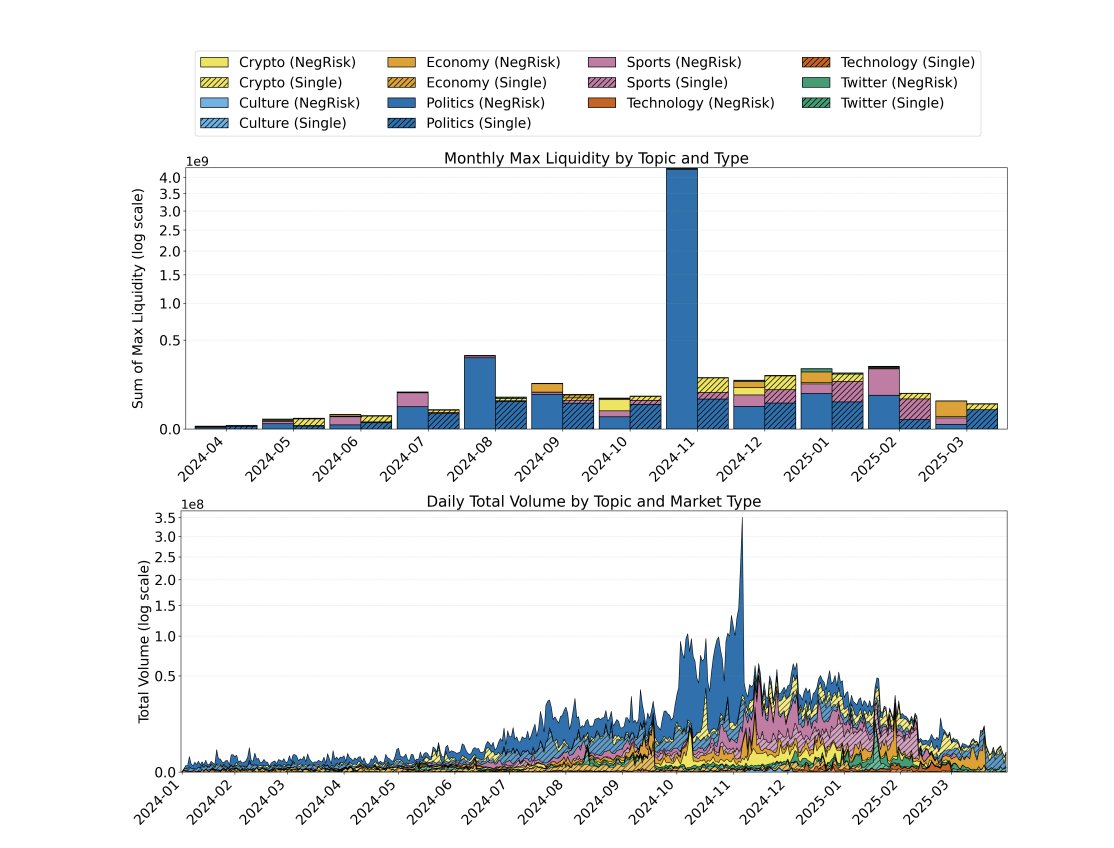
此图表显示了流动性趋势。 机器人必须过滤活跃市场。
对于组合逻辑: 使用 PuLP 进行整数规划。
对于语义匹配: 使用 HuggingFace transformers。
首先构建一个获取脚本: 每 10 秒查询一次。 记录偏差。
稳定性第一。优化随后。
数据收集和机会检测
使用 /markets 列出活跃条件。
然后查询 /prices 获取 VWAP。
将数据存储在 SQLite 中。
为什么?
因为套利窗口很短。 这张图片显示了 bid 差价消失得有多快:
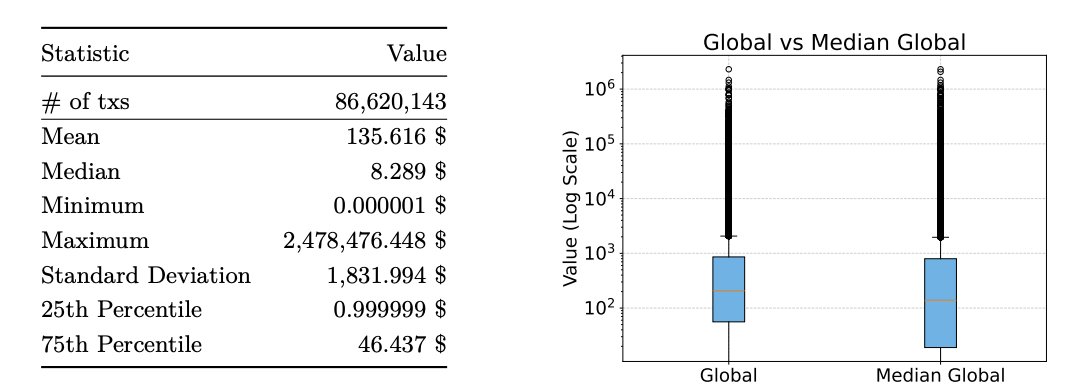
市场内逻辑
如果 ,做空定价过高的一方 如果 ,买入定价过低的一方
仅当偏差 时才行动。
多市场逻辑
使用 LLM 识别依赖关系。 此图表显示了依赖集群:
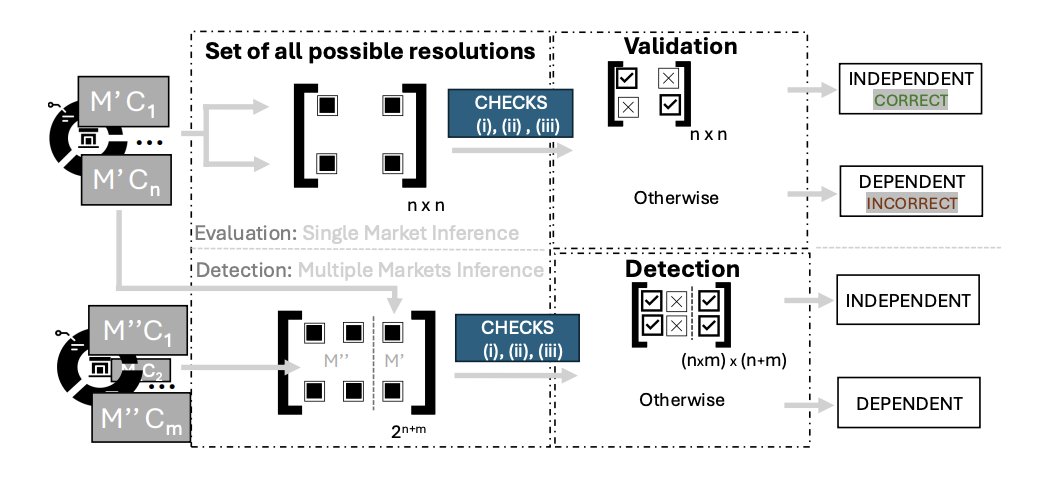
你可以使用 OpenAI API 来语义对齐事件。
这反映了 “Semantic Non-Fungibility and Violations of the Law of One Price in Prediction Markets” 中的框架。
组合检测
将结果空间建模为整数规划。
求解不一致性。
神经网络检测
使用 torch.nn 训练分类器。
输入:价格向量 输出:套利 / 无套利
目标 召回率。
使用子图数据回测。
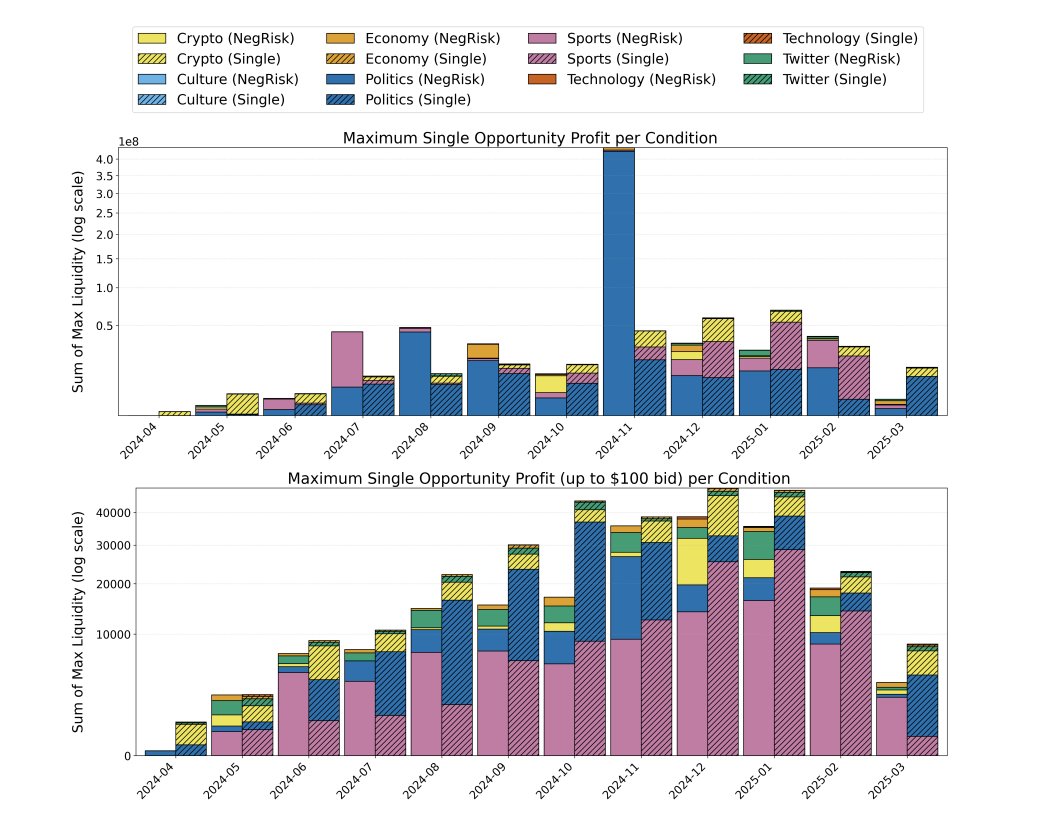
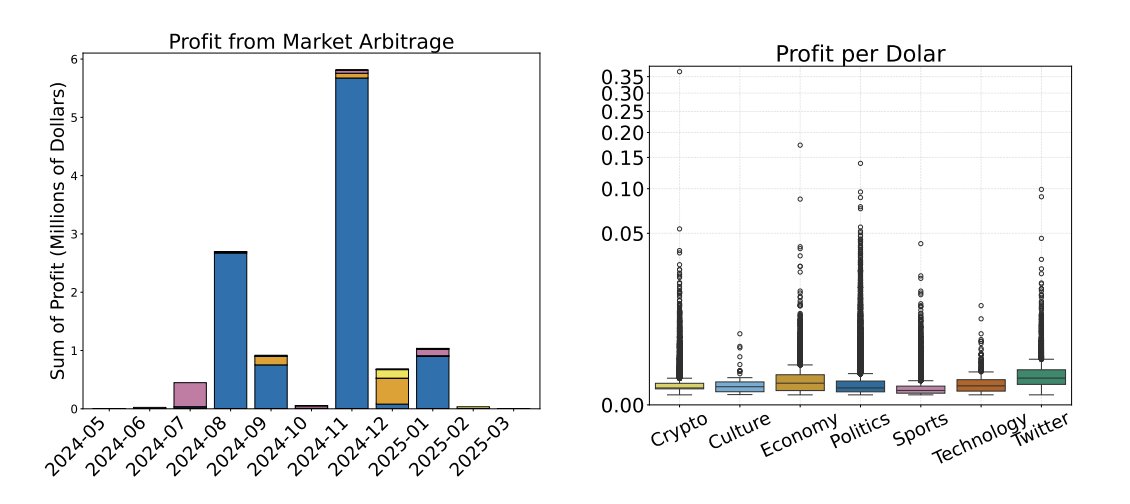
此图表显示利润上限在 $100` 流动性左右。 执行规模很重要。
异步扫描至关重要。 速度就是优势。
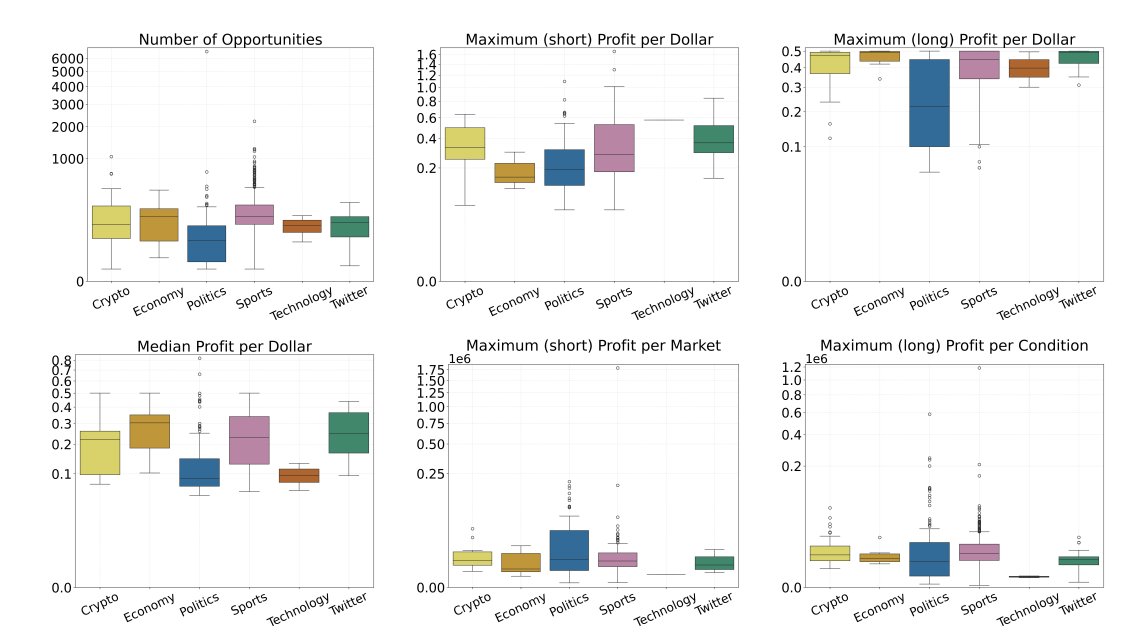
高级检测技术
对于 NegRisk 再平衡:
使用 SciPy 的优化方法。 查看投资组合调整机会:
跨平台:
通过 API 扫描 Kalshi, Manifold。 “Semantic Non-Fungibility and Violations of the Law of One Price in Prediction Markets” 发现事件重叠约 。
那是碎片化流动性的 alpha。
整数规划实现
使用 PuLP:
定义变量 = 头寸大小 约束 = 无损失条件 目标 = 最大化利润
这反映了 “Arbitrage-Free Combinatorial Market Making via Integer Programming”。
神经网络模型
架构:
- 5 个隐藏层
- 学习率 =
特征:
- 价格向量
- 交易量
- 价差
在模拟定价错误上训练。
简单规则会错过复杂的多市场优势。 ML 跨维度扩展检测。
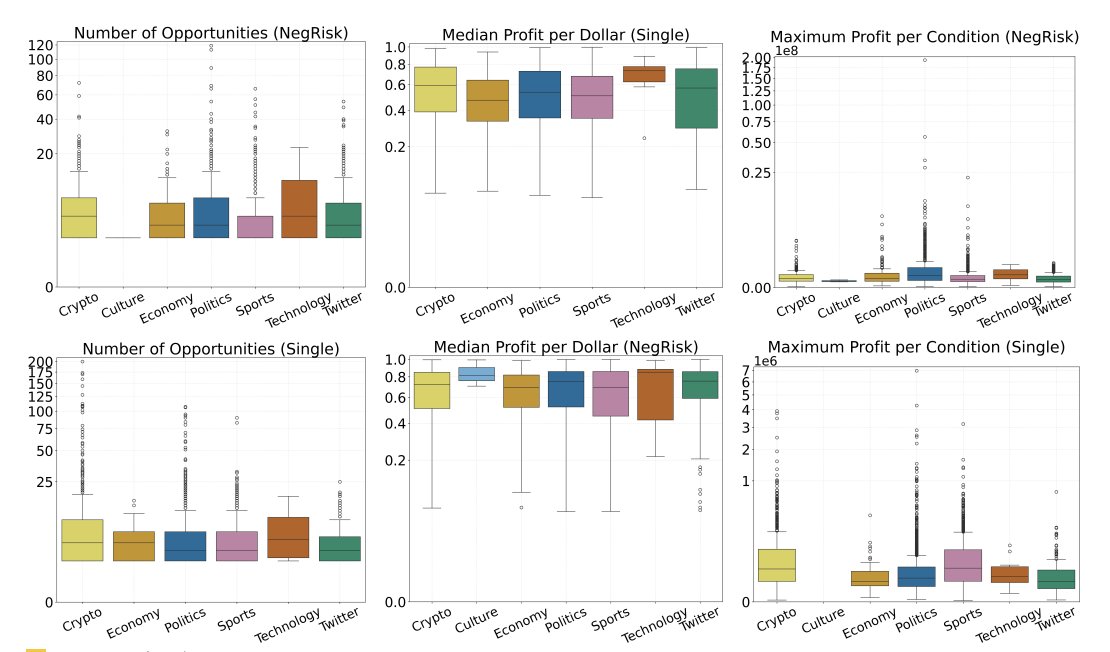
此图表显示多条件市场的表现优于单一条件市场。
如果你要优化,就在那里优化。
执行、风险管理和优化
检测是理论。 执行是赚钱或亏钱的地方。
使用 CLOB /orders 端点。
用 web3 签名。
估算 Gas:
w3.eth.gas_price
风险
- 滑点(使用限价单)
- 抢跑(考虑私有中继)
- 预言机风险(分散事件)
- 流动性上限(模拟成交)
头寸 sizing:
每笔交易风险 <1\% 资本。
如果每日回撤 则停止交易。
优化
针对历史数据集回测。 关注具有重复利用机会的体育市场。 示例市场: https://polymarket.com/sports/nba/nba-bkn-okc-2026-02-20?via=bored2boar
监控夏普比率。 跟踪胜率和执行滑点。
使用 asyncio 进行并发。 部署在 AWS 或类似服务上以实现 24/7 正常运行时间。
超参数调整: 网格搜索学习率和架构。 遵循 “NEURAL NETWORKS CAN DETECT MODEL-FREE STATIC ARBITRAGE STRATEGIES” 中的方法。
此图表显示一致的小赢优于 sporadic 的大赢:
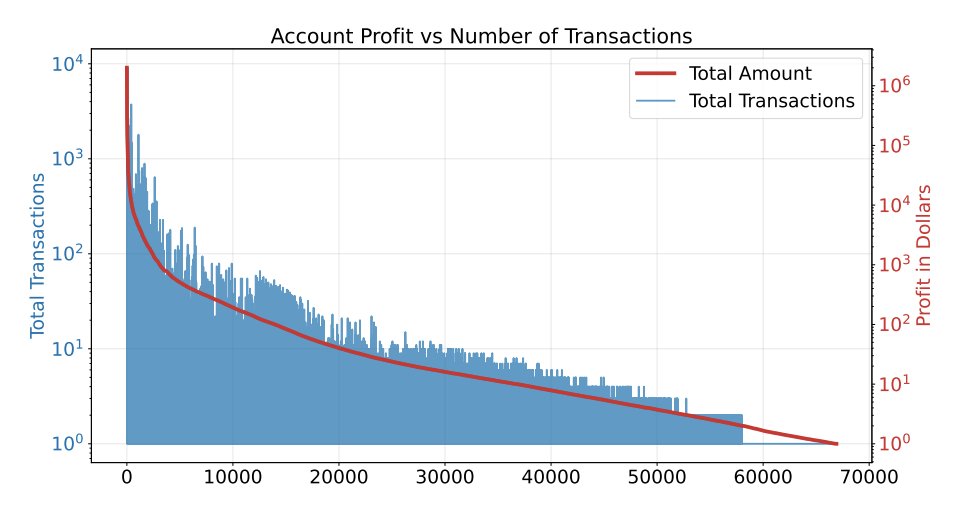
套利是关于复利小优势。
结论和下一步
你现在有了蓝图。
从这里的理论基础开始: https://arxiv.org/pdf/2508.03474
到这里的语义对齐: https://arxiv.org/pdf/2601.01706
到这里的组合定价: https://arxiv.org/pdf/1606.02825
到这里的神经检测: https://arxiv.org/pdf/2306.16422
到这里的 API 执行: docs.polymarket.com
这些是我用于本文的论文,并创建了我自己的机器人,自启动以来已经赚了 $7,800+。
虽然不多,但几个月后这个金额可能会变成 6 位数的净利润。
从简单开始:
- 构建监控器
- 添加检测逻辑
- 回测
- 添加执行
- 逐步扩展
观察多条件利润如何随时间扩展。
套利机器人不创造优势,它们只捕捉低效。
随着 Polymarket 的增长,碎片化也在增长。
碎片化创造定价错误。
那是机会。
但只有你仔细构建才行。
积极测试。
计入交易成本。
模拟流动性。
套利让优势普惠。
但唯有自律的构建者,方能长久拥有。
理性构建,审慎套利。