第三章 基于样本的方法
这章,主要介绍几种用于估算大多数投资组合优化模型所需输入参数的方法:预期收益向量和协方差矩阵。这些方法的主要缺点是:其估算的参数默认假设资产收益的未来表现会与用于估算的样本表现相似。
3.1 矩(moments)
统计学中,矩(moments)是与概率分布形状相关的数值特征。
3.1.1 原始矩(Raw Moments)
1. 什么是矩:物理类比
概率论中的“矩”可与物理学中的“力矩”相类比,以帮助理解。
在物理学中:
- 一阶矩(力矩):
力 × 力臂。描述了“力”对物体转动效果的大小。
- 二阶矩(转动惯量):
质量 × (距离)²。描述了物体抵抗转动的能力。
在概率论中,这种思想被借用来描述随机变量的分布特征:
- 一阶原点矩:对所有
(数值 × 概率) 的求和。它描述了随机变量取值的中心位置,即均值。
- 二阶原点矩:对所有
(数值² × 概率) 的求和。它描述了随机变量取值平方的平均水平,与方差密切相关。
- k阶原点矩:对所有
(数值^k × 概率) 的求和。它描述了随机变量取值k次方的平均水平。
简单来说:第 k 阶原点矩就是随机变量 X 的 k 次方的平均值。
2. 如何计算矩:理论与现实
情况一:理论上(已知精确的概率分布)
如果一个随机变量 X 的精确概率密度函数 f(x) 已知,便可用积分来计算其精确的理论值:
E[Xk]=∫−∞∞xkf(x)dx
- xk: 所关心的数值。
- f(x)dx: 该数值对应的“概率权重”。
- ∫: 对所有可能的 x 值进行“加权求和”。
情况二:现实中(只有观测到的数据)
在现实应用中,通常只有一系列观测到的数据(样本),其精确的概率分布未知。此时,采用求和的方式来估算原点矩:
E[Xk]=i=1∑Tp(xi)xik在最常见的情况下,每个观测值被假设拥有相等的出现概率,即 p(xi)=T1。此时,公式简化为:
样本的k阶原点矩=T1i=1∑Txik3. 重要的矩及其含义
-
一阶原点矩 (均值, Mean)
- 定义: μ=E[X]
- 意义: 代表了随机变量分布的中心位置或平衡点 。它也是最常用、最重要的矩。
-
二阶原点矩 (方差的基石)
- 定义: E[X2]
- 意义: 其本身不直接使用,但它是计算方差 (Variance, σ2) 的关键。方差是衡量数据分散程度(“胖瘦”)的核心指标。
- 关键关系: σ2=E[X2]−(E[X])2=E[X2]−μ2
4.示例
计算一个样本数据集 {2, 3, 4, 5} 的相关矩:
- 一阶原点矩(均值):
μ=E[X]=42+3+4+5=3.5
- 二阶原点矩:
E[X2]=422+32+42+52=44+9+16+25=13.5
- 方差(利用矩的关系计算):
σ2=E[X2]−μ2=13.5−(3.5)2=13.5−12.25=1.25
3.1.2 中心矩 (Central Moments)
1. 什么是中心矩
与围绕“原点(0)”计算的原始矩不同,中心矩是围绕随机变量的“中心 (均值 μ)”来计算的。
如果说原点矩衡量的是变量在数轴上的绝对位置和分布,那么中心矩衡量的则是变量相对于其平均水平的分布形态。
- 原点矩: 杠杆的支点固定在原点0。
- 中心矩: 杠杆的支点移动到了分布的重心 μ。
简单来说:第 k 阶中心矩就是“随机变量与均值的差”的 k 次方的平均值。
2. 如何计算中心矩:理论与现实
情况一:理论上(已知精确的概率分布)
如果一个随机变量 X 的精确概率密度函数 f(x) 已知,其 k 阶中心矩的计算公式为:
E[(X−μ)k]=∫−∞∞(x−μ)kf(x)dx
- (x−μ)k:核心部分,表示数值点到均值的**距离(偏差)**的k次方。
- f(x)dx: 该数值对应的“概率权重”。
情况二:现实中(只有观测到的数据)
在现实应用中,当只有一系列样本数据时,其 k 阶样本中心矩的估算公式为:
E[(X−μ)k]=i=1∑Tp(xi)(xi−μ)k在最常见的情况下,即每个观测值概率相等 (p(xi)=T1),公式简化为:
样本的k阶中心矩=T1i=1∑T(xi−μ)k3. 重要的中心矩及其含义
中心矩是描述概率分布形状的基石,其中二、三、四阶最为常用。
-
二阶中心矩 (方差, Variance)
- 定义: σ2=E[(X−μ)2]
- 意义: 衡量数据围绕均值分散程度的核心指标,即数据的“胖瘦”。方差的平方根是标准差 σ。
-
三阶中心矩 (偏度, Skewness)
- 定义: E[(X−μ)3]
- 意义: 衡量数据分布不对称性的指标,即分布的“歪斜方向”。
- 正偏态 (Positive Skew):分布的尾部在右侧更长。
- 负偏态 (Negative Skew):分布的尾部在左侧更长。
- 零偏态:分布完全对称。
-
四阶中心矩 (峰度, Kurtosis)
- 定义: E[(X−μ)4]
- 意义: 衡量数据分布峰顶的尖锐程度和尾部的厚重程度,常用于判断“离群值”的多少。
- 高峰态 (Leptokurtic):峰顶更尖锐,尾部更厚重(离群值比正态分布多)。
- 低峰态 (Platykurtic):峰顶更平缓,尾部更轻薄(离群值比正态分布少)。
4. 示例
沿用之前的数据集 {2, 3, 4, 5},其均值为 μ=3.5。
-
方差(二阶中心矩):
σ2=41[(2−3.5)2+(3−3.5)2+(4−3.5)2+(5−3.5)2]=41[(−1.5)2+(−0.5)2+(0.5)2+(1.5)2]=41[2.25+0.25+0.25+2.25]=45=1.25
(该结果与使用原始矩计算出的方差完全一致)
-
三阶中心矩(用于判断偏度):
E[(X−μ)3]=41[(−1.5)3+(−0.5)3+(0.5)3+(1.5)3]=41[−3.375−0.125+0.125+3.375]=0
(结果为0,表明该数据集是完全对称的)
3.1.3 标准化中心矩 (Standardized Central Moments)
1. 为什么需要“标准化”?—— 消除量纲,专注形状
在比较不同数据集的分布形状时,我们常常会遇到一个问题:数据的单位或尺度会严重影响矩的数值。
例如,衡量身高数据的“离散程度”(二阶中心矩,即方差),用“米”作单位和用“厘米”作单位,算出来的方差值会相差 1002=10000 倍。这使得我们无法直接比较两个不同尺度数据集的分布形状。
标准化的目的,就是通过除以标准差(sigma)的相应次方,来剔除单位和尺度的影响,得到一个“纯粹”的、无量纲的数值。这个数值只描述分布的内在形状特征(如对称性、尾部厚度),而与数据本身的绝对大小无关。
简单来说:标准化让我们能公平地比较一个身高分布和一个体重分布的“形状”。
2. 标准化矩的定义
第 k 阶标准化矩 (tildemu_k) 的计算方法是,将第 k 阶中心矩 (mu_k) 除以标准差 (sigma) 的 k 次方。
μ~k=σkμk=(E[(X−μ)2])kE[(X−μ)k]
- 分子 μk: 第 k 阶中心矩,描述了数据相对于均值的分布情况。
- 分母 σk: 标准差的 k 次方,作为一个“标准化因子”,消除了数据自身的尺度和量纲。
在实际应用中,我们最关心的是三阶和四阶标准化矩,它们有专门的名称:偏度 (Skewness) 和 峰度 (Kurtosis)。
3. 两个最重要的标准化矩:偏度与峰度
3.1 偏度 (Skewness) - 衡量分布的“不对称性”
3.2 峰度 (Kurtosis) - 衡量分布的“尾部厚度”
-
定义: 第四阶标准化矩,记为 μ~4。
Kurtosis=μ~4=σ4E[(X−μ)4]
-
意义: 描述了数据分布尾部的厚重程度,即出现极端值(离群值)的倾向性。
-
关键点:超额峰度 (Excess Kurtosis)
- 正态分布的峰度计算出来恰好等于 3。
- 为了方便比较,统计学家费雪(Fisher)提出了超额峰度的概念,即将计算出的峰度值减去 3。
- 超额峰度 = 峰度 - 3
- 这样,正态分布就成了一个完美的基准点,其超额峰度为 0。现在大部分统计软件计算的都是超额峰度。
-
解读 (基于超额峰度):
-
超额峰度>0 (尖峰态, Leptokurtic):
- 分布的峰部更“尖”,尾部更“厚实”。
- 这意味着出现极端值(离群值)的概率比正态分布更高。
- 例子:股票市场的日收益率分布,大部分时间波动很小(尖峰),但偶尔会出现极端的大涨或大跌(厚尾)。
-
超额峰度≈0 (正态峰, Mesokurtic):
-
超额峰度<0 (平峰态, Platykurtic):
- 分布的峰部更“平缓”,尾部更“薄”。
- 这意味着出现极端值的概率比正态分布更低。
- 例子:均匀分布,其取值范围内各数值出现概率相等,没有极端离群值。
3.1.4 协矩矩阵 (Comoments Matrices)
1. 核心概念:什么是协矩矩阵?
在金融分析中,我们不仅关心单个资产的风险与收益特性(如方差、偏度),更关心由多个资产构成的投资组合(Portfolio) 的整体特性。协矩矩阵正是用于计算多个随机变量线性组合(即投资组合) 的高阶矩的强大工具。
- 目的: 将描述单个资产的“矩”(方差、偏度、峰度)推广到多资产的“协矩”(协方差、协偏度、协峰度)。
- 本质: 它是我们熟悉的协方差矩阵向更高阶的自然延伸。
想象一下,你之前学的原点矩和中心矩(如均值、方差、偏度、峰度)是描述单个随机变量(比如一只股票)的特征。
- 均值:这只股票的平均收益率。
- 方差:这只股票的收益率波动有多大。
- 偏度:这只股票的收益率分布是左偏(常出现小跌)还是右偏(常出现小涨)。
- 峰度:这只股票的收益率出现极端大涨大跌(尾部风险)的可能性有多高。
但现在问题来了:当你把多只股票组合在一起形成一个投资组合时,这个组合的矩(比如组合的方差、偏度、峰度)该怎么计算?
你可能会想:“直接把每只股票的方差平均一下不就得了?”——这是错误的。因为股票之间会有关联(协方差),组合的风险并不是个体风险的简单加总。这就是协矩矩阵要解决的问题。
协矩矩阵的核心目的,就是计算一个投资组合的高阶矩(方差、偏度、峰度等)。
2. 什么是“协矩”?
“协”指的是变量间“协同”、“关联”的统计关系。所以:
- 协方差矩阵 (
M₂) 其实就是 二阶中心协矩矩阵。它描述了任意两只资产之间的协同波动关系。
- 协偏度矩阵 (
M₃) 是 三阶中心协矩矩阵。它描述了三个变量之间的协同偏斜关系。比如,资产A大涨时,资产B和C同时大跌的关联特性。
- 协峰度矩阵 (
M₄) 是 四阶中心协矩矩阵。它描述了四个变量之间产生协同极端走势的可能性。
这些矩阵(M₂, M₃, M₄ … Mₖ)就是接下来公式里那些看起来复杂的东西,它们是由所有单个资产的收益率数据R计算出来的。可以把它们看作是预先计算好的“原料”或“数据库”,里面存储了所有资产之间不同阶次的相互作用关系。
2. 如何计算:协矩矩阵 M_k 的构建
协矩矩阵 Mk 是基于中心化收益率矩阵 Z 计算的,其中 Z=R−μ′,即原始收益率矩阵 R 的每一列减去其各自的时间序列均值。
A. 具体公式
根据 Cajas (2022) 提出的矩阵公式,前几阶协矩矩阵计算如下:
- 二阶协矩 (协方差矩阵, M2):
M2=T1[Z′Z]
- 三阶协矩 (协偏度矩阵, M3):
M3=T1[Z′((Z⊗1n′)⊙(1n′⊗Z))]
- 四阶协矩 (协峰度矩阵, M4):
M4=T1[Z′((Z⊗1n′)⊙(1n′⊗Z⊗1n′)⊙(1n′⊗1n′⊗Z))]
符号解释:
- Z: T×n 的中心化收益率矩阵。
- T: 时间序列的观测数量。
- n: 资产数量。
- 1n: n×1 的全1列向量。
- ⊗: 克罗内克积 (Kronecker Product),将矩阵进行分块扩展。
- ⊙: 哈达玛积 (Hadamard Product),同尺寸矩阵的逐元素相乘。
B. 通用公式
对于任意 k 阶协矩矩阵,其通用计算范式为:
Mk=T1[Z′(i=1⨀k−1Wik−1)]
其中辅助矩阵 Wis 是一个由 s 个矩阵通过克罗内克积构成的矩阵,其中只有第 i 个位置是 Z,其余位置都是全1矩阵 1n′。
Wis=1n′⊗1n′⊗…⊗positioniZ⊗…⊗1n′⊗1n′selements3. 核心应用:计算投资组合的各阶矩
计算出协矩矩阵 Mk 后,其主要用途是结合投资组合的权重向量 x (n×1 向量),来计算整个投资组合的整体矩 μk。
方法一:标准公式 (Standard Formula, 式 3.8)
这是最直观的表达方式。
μk=x′Mkk−1 times(x⊗...⊗x)
具体展开为:
- μ1=x′M1
- μ2=x′M2x
- μ3=x′M3(x⊗x)
- μ4=x′M4(x⊗x⊗x)
方法二:向量化公式 (Vectorized Formula, 式 3.9)
通过使用向量化算子 vec(.),可以将矩阵乘法转换为向量内积,这在某些数学证明和计算中更方便。
μk=vec(Mk)′(k timesx⊗…⊗x)方法三:降维向量化公式 (Reduced Vectorized Formula, 式 3.10)
当 Mk 内部存在对称性和冗余时,可以使用特殊的“消除矩阵” Lk 和“求和矩阵” Sk 来减少计算中涉及的参数数量,提高计算效率。
μk=[Skvec(Mk)]′[Lkk times(x⊗…⊗x)]4. 特殊协矩矩阵及其应用
A. 平方协矩矩阵 (Squared Comoments Matrices, Σ2k)
这类矩阵专门用于处理偶数阶矩(如方差、峰度),其目的是将投资组合的偶数阶矩表示为一个二次型 (Quadratic Form)。
- 定义: Σ2k 是一个 nk×nk 的对称矩阵,可以看作是 M2k 的一种“堆叠”版本。
- 计算 (式 3.7):
- Σ2=M2=T1[Z′Z]
- Σ4=T1[((Z⊗1n′)⊙(1n′⊗Z))′((Z⊗1n′)⊙(1n′⊗Z))]
- 应用 (二次型表达):
μ2k=(k timesx⊗…⊗x)′Σ2k(k timesx⊗…⊗x)
例如,峰度可以写作 μ4=(x⊗x)′Σ4(x⊗x)。这种形式在投资组合优化问题中非常有用。
B. 半协矩矩阵 (Semi Comoments Matrices)
在风险管理中,投资者更关心亏损(下行风险)。半协矩矩阵正是为了分离上行和下行风险而设计的。
- 计算: 方法与标准协矩矩阵完全相同,仅需在第一步修改中心化收益率矩阵 Z:
- 下半协矩 (Lower Semi-comoments): 只使用收益率低于均值(即亏损)的数据,只关注亏损。令 Z=min(R−μ′,0)=min(CTR,0)。
- 上半协矩 (Upper Semi-comoments): 只使用收益率高于均值(即盈利)的数据,只关注盈利。令 Z=max(R−μ′,0)=max(CTR,0) 。
C. 峰度计算的替代公式 (Alternative Kurtosis Formulas)
原文最后提供了两个专门用于计算投资组合峰度 μ4 的高效公式,它们利用了张量积的对称性,结合 L2 和 S2 矩阵来进一步减少参数数量。
- 公式 3.12: μ4=[(S2⊗S2)vec(M4)]′[(L2⊗L2)(x⊗x⊗x⊗x)]
- 公式 3.13: μ4=[L2(x⊗x)]′[S2Σ4S2′][L2(x⊗x)]
3.1.5 线性矩或L矩 (Linear Moments or L-Moments)
1. 什么是L矩:一种更稳健的分布描述方法
L矩是描述概率分布形状(如中心位置、离散程度、偏斜度等)的另一种方法,可以看作是传统中心矩(均值、方差、偏度、峰度)的替代方案。
其核心思想基于两个关键概念:
- 顺序统计量 (Order Statistics):在计算前,必须先将数据集从小到大排序。
- 线性组合 (Linear Combination):L矩是通过对这些排好序的数据进行加权求和来计算的。
与传统矩的核心区别与优势:
- 传统矩:使用数据的幂(如 x2,x3)进行计算。这种方法对数据集中的极端值(异常值)非常敏感,一个很大的异常值在平方或立方后会不成比例地影响最终结果。
- L矩:只使用数据的线性组合(即加权平均)。这使得L矩对异常值的存在更加稳健 (Robust),其计算结果不会被少数几个极端值严重扭曲。
简单来说,L矩提供了一种与传统矩功能相似但更不容易受极端值影响的工具,尤其适用于金融等可能出现“肥尾”现象的数据。
2. 如何计算L矩:加权求和的艺术
计算L矩的第一步永远是将样本数据排序。假设我们有一个大小为 T 的样本,排序后得到:
y[1]<y[2]<⋯<y[i]<⋯<y[T]
其中 y[i] 是第 i 小的数据点。
第 k 阶L矩 (λk) 的一般形式可以理解为一个对排序后数据的加权平均值:
λk=(kT)−11≤i1<i2<⋯<ik≤n∑k1j=0∑k−1(−1)j(jk−1)y[ik−j](3.14)λk=i=1∑Twiky[i]
这个公式的含义是,为了计算第 k 阶L矩,每一个排好序的数据点 y[i] 都会被赋予一个特定的权重 wik,然后将它们相乘后求和。这些权重的计算方式比较复杂(如原文公式3.16所示),但其最终目的都是为了衡量分布的不同特征。
3. 四个最重要的L矩
对于一个已排序的样本,前四阶L矩的具体计算公式如下,它们分别对应传统矩中的均值、方差、偏度和峰度。
-
一阶L矩 (λ1):L-位置 (L-location)
- 公式: λ1=(1T)−1∑i=1Ty[i]=T1∑i=1Ty[i]
- 意义: 它衡量的就是分布的中心位置,其计算结果与样本均值 (Mean) 完全相同。
-
二阶L矩 (λ2):L-尺度 (L-scale)
- 公式: λ2=21(2T)−1∑i=1T[(1i−1)−(1T−i)]y[i]
- 意义: 衡量数据的离散程度,是方差或标准差的稳健替代品。
-
三阶L矩 (λ3):L-偏度 (L-skewness)
- 公式: λ_3=31(3T)−1∑_i=1T[(2i−1)−2(1i−1)(1T−i)+(2T−i)]y[i]
- 意义: 衡量分布的不对称性,是偏度 (Skewness) 的稳健替代品。
-
四阶L矩 (λ4):L-峰度 (L-kurtosis)
- 公式: λ4=41(4T)−1∑i=1T[(3i−1)−3(2i−1)(1T−i)+3(1i−1)(2T−i)−(3T−i)]y[i]
- 意义: 衡量分布尾部的厚重程度,是峰度 (Kurtosis) 的稳健替代品。
4. L矩与中心矩的关系
尽管计算方法不同,L矩和中心矩通常是用来描述同一分布的不同方面。在金融时间序列等应用场景中,这两种矩之间常常存在着正相关关系。这意味着,当一个分布的中心矩(如方差)较高时,其对应的L矩(L-尺度)通常也较高。
下图(Fig. 3.1)直观地展示了这种关系,图中显示了某资产(APA)的中心矩和L矩之间的散点图,可以清晰地看到一个正向的线性趋势。
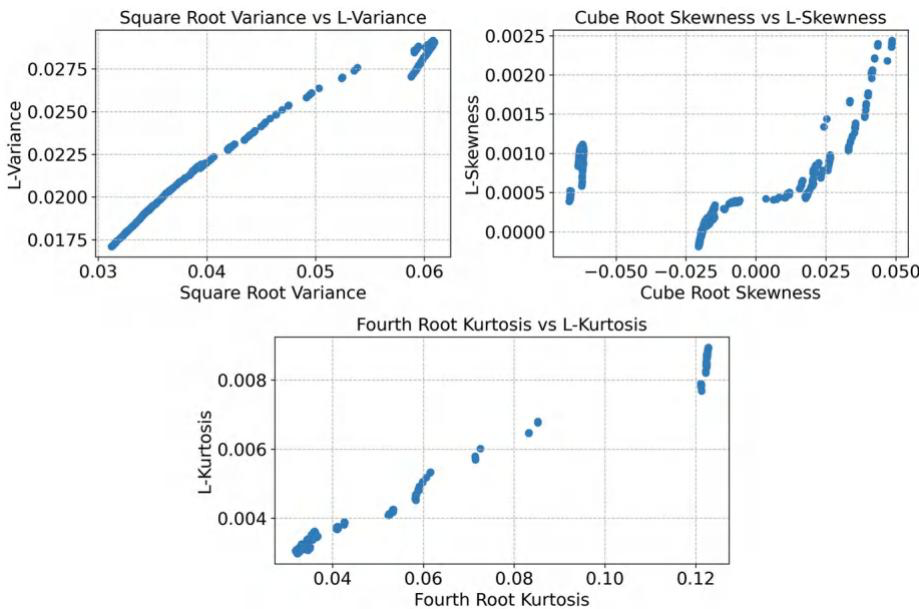
Fig. 3.1 APA的中心矩与L矩的相关性
这组散点图展示了APA(某一研究对象,可能是资产、数据集等)的中心矩和对应的L矩之间的相关关系:
- Square Root Variance vs L - Variance:图中显示“平方根方差(Square Root Variance)”和“L - 方差(L - Variance)”呈现出较强的线性正相关趋势,随着平方根方差的增大,L - 方差也大致按比例增大,说明二者在方差维度上具有较好的关联性。
- Cube Root Skewness vs L - Skewness:“立方根偏度(Cube Root Skewness)”和“L - 偏度(L - Skewness)”同样存在正相关关系,不过数据点的分布相对更分散一些,但整体上随着立方根偏度的增加,L - 偏度也有上升的趋势,反映出偏度维度上二者的关联。
- Fourth Root Kurtosis vs L - Kurtosis:“四次方根峰度(Fourth Root Kurtosis)”与“L - 峰度(L - Kurtosis)”也表现为正相关,数据点从左下方到右上方分布,表明在峰度维度上,中心矩和L矩也存在一定的关联。
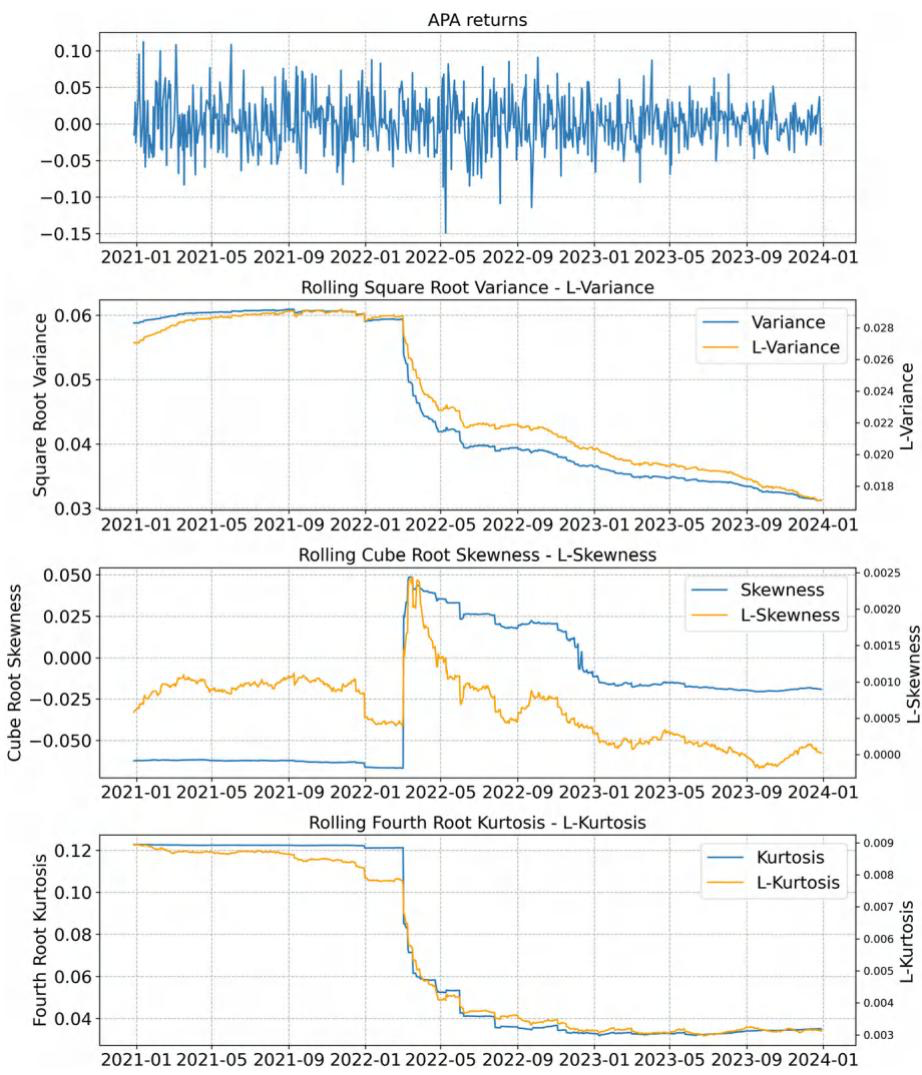 Fig. 3.2 APA的滚动窗口中心矩和L矩
Fig. 3.2 APA的滚动窗口中心矩和L矩
这组图是基于滚动窗口(随着时间推移,不断更新窗口内的数据来计算统计量)计算的中心矩和L矩的时间序列变化:
- APA returns:展示了APA回报的时间序列,回报在不同时间点有波动,存在正负变化,反映了研究对象在这段时间内的收益波动情况。
- Rolling Square Root Variance - L - Variance:“滚动平方根方差(Rolling Square Root Variance)”和“L - 方差(L - Variance)”的时间序列走势较为相似,整体都有从高到低的变化趋势,说明在滚动计算的情况下,方差和L - 方差的变化规律较为一致。
- Rolling Cube Root Skewness - L - Skewness:“滚动立方根偏度(Rolling Cube Root Skewness)”和“L - 偏度(L - Skewness)”的时间序列在不同时间段有不同的波动,不过整体上二者的变化趋势存在一定的同步性,体现了偏度和L - 偏度在滚动计算时的变化关联。
- Rolling Fourth Root Kurtosis - L - Kurtosis:“滚动四次方根峰度(Rolling Fourth Root Kurtosis)”与“L - 峰度(L - Kurtosis)”的时间序列走势也较为接近,随着时间推移,都有明显的下降等变化,反映出峰度和L - 峰度在滚动窗口下的变化规律具有一致性。
3.2 指数加权移动平均 (EWMA)
指数加权移动平均(Exponentially Weighted Moving Average, EWMA)是一种重要的时间序列预测方法。它通过对历史数据进行加权平均来预测下一个时间点的值,其核心思想是:越近的数据越重要,权重越大;越远的数据越不重要,权重越小。权重的下降(衰减)遵循指数规律。
1. 核心思想:权重如何“指数衰减”?
想象一下预测明天的股票价格。你自然会觉得昨天和前天的价格比一年前的价格更有参考价值。EWMA 正是这种直觉的数学化表达。
它为每一个历史数据点 xt−j 分配一个权重,这个权重由一个关键参数——平滑因子 (smoothing factor) λ (取值范围为 0≤λ<1)——来控制。
- 权重:距离现在为 j 个时间步的数据点,其权重与 λj 成正比。
- 衰减:因为 λ 是一个小于1的正数,所以当 j 增大时(即数据越久远),λj 会迅速趋近于零。
平滑因子 λ 的角色:
λ 决定了“记忆”的长短,或者说对历史数据的遗忘速度。
- 当 λ 趋近于 1 (例如 0.95):
- 衰减慢,权重曲线平缓。
- 模型会考虑非常久远的历史数据,记忆性强。
- 输出结果更平滑,不易受短期噪声影响,但对趋势变化的反应较慢。
- 当 λ 趋近于 0 (例如 0.1):
- 衰减快,权重曲线陡峭。
- 模型主要依赖最近的几个数据点,记忆性短。
- 输出结果波动性更大,但能非常迅速地捕捉到近期的变化。
2. 如何计算 EWMA:两种等价的公式
方法一:理论定义式 (无限历史)
EWMA 的数学定义是对所有历史数据进行加权求和:
x^t+1=(1−λ)j=0∑∞λjxt−j(3.17)
- xt−j: 过去的数据点(当 j=0 时,为当前数据 xt)。
- λj: 权重随时间衰减的核心部分。
- (1−λ): 归一化因子。根据数学公式,所有权重的无限求和 ∑j=0∞λj 恰好等于 1−λ1。因此,乘以 (1−λ) 可以保证所有权重加起来正好等于 1。
方法二:递归计算式 (高效实用)
在实际应用中,对无穷序列求和是不可能的。幸运的是,上述公式可以转化为一个极其简洁高效的递归形式:
x^t+1=λx^t+(1−λ)xt(3.19)
- x^t+1: 对下一个时间点的预测值。
- x^t: 对当前时间点的预测值(它本身已包含了 t 之前的所有历史信息)。
- xt: 当前时间点的实际观测值。
这个公式的含义可以理解为:新的预测 = λ 成的旧预测 + (1−λ) 成的新信息。它巧妙地将所有历史信息压缩在了上一个预测值 x^t 中,每次更新只需一步,极大简化了计算。
实践提示:在很多软件库(如 Python 的 Pandas)中,常使用参数 alpha (α)。它与 λ 的关系是 α=1−λ。因此,一个小的 alpha 值等价于一个大的 λ 值,都代表着更强的平滑效果(更慢的衰减)。
3. EWMA 的应用:估计均值和协方差
EWMA 的强大之处在于,这种递归更新的思想可以推广到更复杂的统计量,尤其在金融领域,常用于动态估计随时间变化的均值向量和协方差矩阵。
-
EWMA 均值 (μewma):
μewma,t+1=λμ^t+(1−λ)rt
其中,rt 是当前时刻的资产回报向量,μ^t 是上一时刻估计的均值向量。
-
EWMA 协方差 (Σewma):
Σewma,t+1=λΣ^t+(1−λ)ϵtϵt′
其中,Σ^t 是上一时刻估计的协方差矩阵,ϵt=rt−μ^t 是当前回报的“意外”部分。
4. 有限样本的调整
当只有有限的 T 个观测数据时,理论公式的权重之和并不严格为 1。为了修正这个偏差,需要对权重进行归一化,得到适用于有限样本的“完整公式”:
x^t+1=1−λT1−λj=0∑Tλjxt−j(3.21)关键结论:当观测数据量 T 很大时,分母 (1−λT) 会非常接近 1,此时该“完整公式”的计算结果与“递归公式”几乎完全相同。因此,在绝大多数应用场景中,简洁高效的递归公式是首选。
3.3 多元时间序列
向量自回归(VAR)、向量移动平均(VMA)和带移动平均的向量自回归(VARMA)模型是AR、MA和ARMA模型在多元情况下的推广。这些模型能够捕捉多个时间序列之间的线性相互依赖关系,并且不需要像联立方程模型那样了解不同变量之间存在的关系;它们只需要为每个变量建立一个方程即可。
3.3.1 向量自回归模型 (Vector Autoregressive Models)
向量自回归 (VAR) 模型是一种用来分析和预测多个相关时间序列变量的强大工具。不同于一次只分析一个变量的模型,VAR模型可以同时捕捉一组变量之间的动态关系。
1. 核心思想:从“我”的过去预测“我”的未来,到从“我们”的过去预测“我们”的未来
想象一下预测天气。只用今天的气温来预测明天的气温是一个简单的自回归 (AR) 模型。但实际上,明天的气温不仅受今天气温的影响,还可能受今天湿度、风速等因素的影响。
向量自回归 (VAR) 模型正是将这种思想扩展到了多个变量。它假设一个系统中所有变量的未来值,都可以用这个系统中所有变量的过去值来预测。
- 向量 (Vector): 代表我们将多个变量 (例如:GDP、利率、通货-膨胀率) 作为一个整体 (向量) 来进行建模。
- 自回归 (Autoregressive): 代表模型使用变量自身的过去值来进行预测。
- 阶数 p (Order p): 代表模型使用了过去多少期的数据。一个 VAR(p) 模型会使用直到 p 期之前的所有历史数据。
2. VAR(p) 模型的数学表达
一个包含 n 个变量的 p 阶 VAR 模型可以用一个简洁的矩阵方程来表示:
yt=c+A1yt−1+…+Apyt−p+ϵt
- yt: 一个 n×1 的向量,包含了在时间点 t 时所有 n 个变量的观测值。
- c: 一个 n×1 的截距向量,代表每个变量的基准水平。
- A1,…,Ap: 一系列 n×n 的系数矩阵。这是 VAR 模型的核心,矩阵中的每个元素都描述了一个变量的过去值对另一个变量当前值的影响力。
- yt−1,…,yt−p: 包含了所有变量在过去 p 个时间点的观测值的滞后向量。
- ϵt: 一个 n×1 的误差向量,代表了在时间点 t 发生的、无法被模型历史信息所解释的“新息”或“冲击”(shock)。
3. 关于“冲击”的假设
模型对误差项(或称冲击)ϵt 有三个关键假设:
- 均值为零: E[ϵt]=0
- 含义: 平均而言,随机冲击不大也不小,没有系统性的预测偏差。
- 同期相关,但方差稳定: E[ϵtϵt′]=Σϵ
- 含义: 在同一时间点 t,一个变量受到的冲击可能会与另一个变量受到的冲击相关。这些同期相关性被包含在协方差矩阵 Σϵ 中。
- 跨期不相关: E[ϵtϵs′]=0, 对于所有 t=s
- 含义: 今天的冲击和昨天的冲击之间没有关联。需要特别注意的是,这个假设仅针对不可预测的“冲击”ϵt。变量 yt 本身通过模型结构,其过去值和现在值是高度相关的,这正是模型所要描述的动态过程。
4. 从动态模型到长期均衡
为了求解模型的长期性质(如均值),我们可以使用滞后算子 (Lag Operator) L 进行代数变换,其中 Lyt=yt−1。这个过程清晰地展示了如何从一个动态关系中找到其静态的均衡点。
- 原始模型:
yt=c+A1yt−1+…+Apyt−p+ϵt
- 用滞后算子改写:
yt=c+(A1L+…+ApLp)yt+ϵt
- 将包含 yt 的项移到左边:
(I−A1L−…−ApLp)yt=c+ϵt
- 求解 yt:
yt=(I−A1L−…−ApLp)−1(c+ϵt)
这个最终形式表达了 yt 是所有历史冲击和常数项的函数。
这个形式上的“解”具有非常深刻的数学和经济学含义,它表达了:当前的经济状态 yt,是由所有历史冲击 (c+ϵt,ϵt−1,ϵt−2,...) 通过系统 [I−A1L−...−ApLp]−1 不断传导和叠加而形成的。
5. 模型的长期性质
所有关于长期性质的讨论都有一个重要前提:VAR系统是平稳的 (Stationary)。这意味着冲击的影响会随时间逐渐消失,系统最终会回归其长期均值。
-
长期均值向量 (μ):
对上式两边取数学期望 E[⋅],并利用 E[ϵt]=0(冲击的均值为零)和 E[yt]=μ(长期均值),可以得到:
μ=(In−A1−⋯−Ap)−1c
含义: 这是模型在稳定状态下,各个变量将围绕其波动的长期平均水平或均衡点。它完全由模型的“结构”——截距 c 和系数矩阵 A1,…,Ap——决定。
-
协方差矩阵分析:
在VAR模型中有两个必须严格区分的协方差矩阵:
-
扰动项的协方差矩阵 (Σϵ):
- 定义: Σϵ=E[ϵtϵt′]
- 含义: 它度量的是模型中不可预测的**“新息”或“冲击”** 🌊 的波动性,以及这些冲击在同一时刻(同期)的相关性。
- 重要性: 在实证分析中,Σϵ 是我们重点关注和估计的对象。它揭示了系统外部冲击的结构,是进行脉冲响应分析和方差分解的基础。
-
变量本身的长期协方差矩阵 (Σy):
- 定义: Σy=E[(yt−μ)(yt−μ)′]
- 含义: 它衡量的是变量 yt 自身在长期均衡状态下的总波动性及变量间的总相关性。yt 的波动不仅来源于当期冲击 ϵt,还累积了所有历史冲击通过系数矩阵 Aj 不断传导和叠加的影响。
- 类比: 如果说 Σϵ 描述的是投入湖中的石子本身的特性,那么 Σy 描述的就是由这颗石子以及所有先前的石子共同产生的最终水面波纹的特性。因此,Σy 通常远比 Σϵ 更大、更复杂。
- 计算: Σy 的计算需要求解专门的矩阵方程(如李雅普诺夫方程),并非一个简单的等式。因此,任何形如
Σ_y = Σ_ε 的表述都是不正确的。
3.3.2 向量移动平均模型 (Vector Moving Average Models)
向量移动平均 (VMA) 模型是分析多变量时间序列的另一个核心工具。它提供了一个与VAR模型互补的视角:VAR关注变量自身的惯性(用过去值预测未来),而VMA则关注外部冲击的持续效应(用过去的预测误差解释当前值)。
1. 核心思想:冲击的涟漪效应
让我们回到平静湖面的比喻。
- VAR 模型关心的是波纹本身的传播规律:“一个波纹会引起下一个波纹”。它用 yt−1 来预测 yt。
- VMA 模型则关心的是最初那颗石子所激起的涟漪会持续多久:“今天的波纹是现在这颗石子,加上昨天那颗石子,再加上前天那颗石子共同作用的结果”。它用过去的“冲击” ϵt−1,ϵt−2,… 来预测 yt。
简单来说,VMA 模型认为,一个系统的当前状态,是其基准水平(一个常数)、当前的随机冲击、以及过去一系列冲击的滞后效应共同决定的。
- 向量 (Vector): 代表我们同时建模多个变量。
- 移动平均 (Moving Average): 模型是当前和过去若干期冲击(误差项) 的加权平均。“移动”体现在我们总是用最近 q 期的冲击来进行解释。
- 阶数 q (Order q): 代表模型考虑了过去多少期的冲击。一个 VMA(q) 模型会使用直到 q 期之前的冲击。
2. VMA(q) 模型的数学表达
一个包含 n 个变量的 q 阶 VMA 模型的矩阵形式如下:
yt=c+B1ϵt−1+…+Bqϵt−q+ϵt(3.27)
- yt: 一个 n×1 的向量,包含了在时间点 t 时所有 n 个变量的观测值。
- c: 一个 n×1 的截距向量,代表每个变量的基准水平或长期均值。
- B1,…,Bq: 一系列 n×n 的系数矩阵。这是VMA模型的核心,矩阵中的每个元素 bi,jk 度量了第 j 个变量在 t−k 期受到的冲击,对第 i 个变量在 t 期值的影响力度。这些矩阵直接对应脉冲响应函数。
- ϵt−1,…,ϵt−q: 过去 q 期的冲击(误差)向量。
- ϵt: 当期的冲击向量,代表全新的、无法预测的“新闻”。
关于误差项 ϵt 的假设与VAR模型完全相同:
- E[ϵt]=0 (均值为零)
- E[ϵtϵt′]=Σϵ (同期相关)
- E[ϵtϵs′]=0,∀s=t (跨期不相关)
3. 滞后算子形式与模型含义
使用滞后算子 L (Lϵt=ϵt−1),VMA模型可以表示为非常简洁的形式:
yt=c+(I+B1L+…+BqLq)ϵt(3.29)
这个形式深刻地表明:当前的经济状态 yt,可以看作是所有当期及历史冲击 ϵt,ϵt−1,...,ϵt−q 通过系统 (I+B1L+…+BqLq) 过滤后形成的线性组合。 系数矩阵 Bj 清晰地刻画了各个历史冲击对当前状态的贡献力度和模式。
4. 模型的长期性质
基于模型表达式和误差项的假设,我们可以推导出系统的长期性质。
-
长期均值向量 (μ):
对模型两边取期望,并利用 E[ϵt]=0:
E[yt]=c+B1E[ϵt−1]+…+BqE[ϵt−q]+E[ϵt]=c
因此,截距向量 c 就是变量的长期均值向量: μVMA(q)=c。这意味着,尽管短期内系统会因各种冲击而波动,但长期来看,这些冲击的影响会相互抵消,系统将回归到其固有的均值水平 c。
-
长期协方差矩阵 (Σy):
变量 yt 的协方差矩阵需要计算 E[(yt−c)(yt−c)′]。将 yt−c=B1ϵt−1+…+Bqϵt−q+ϵt 代入后,利用冲击无自相关的性质,所有不同期冲击的交叉项期望均为零。最终结果为:
ΣVMA(p)=E[(yt−E[yt])(yt−E[yt])′]=Σϵ+j=1∑qBjΣϵBj′
含义: 这个公式清晰地展示了变量 yt 总波动性的来源。
- Σϵ: 这是由当前冲击 ϵt 直接贡献的波动性。
- ∑j=1qBjΣϵBj′: 这是由过去 q 个冲击的“涟漪效应”贡献的波动性之和。每一项 BjΣϵBj′ 都表示第 j 期前的冲击(其原始波动性为 Σϵ)经过系数矩阵 Bj 的传导和变换后,对当前 yt 波动性的贡献。
这个公式在结构上是清晰且正确的,它明确地将当前波动性分解为了当前冲击和历史冲击两部分贡献的总和。
3.3.3 向量自回归移动平均模型 (Vector Autoregressive Moving Average Models)
向量自回归移动平均 (VARMA) 模型是 VAR 和 VMA 模型的综合与推广。它结合了二者的特点,认为系统的当前状态既受到其自身过去值的影响(自回归部分),也受到历史冲击的影响(移动平均部分)。这使得 VARMA 模型能够更灵活、更通用地描述多变量时间序列的动态规律。
1. 核心思想:结合“惯性”与“记忆”
VARMA模型的基本思想非常直观:一个系统的当前状态,既受其自身过去状态的持续影响,也受过去随机冲击的滞后效应影响。
- VAR部分: 捕捉了系统的“动量”或“惯性”。例如,经济增长昨天很高,今天可能也倾向于较高。
- VMA部分: 捕捉了系统对“意外”或“冲击”的“记忆”。例如,上个月的供应链冲击,其负面影响可能持续到今天。
简单来说,VARMA = VAR + VMA。它提供了一个更完整的画面,认为 yt 是由 yt−p (过去的值) 和 ϵt−q (过去的冲击) 共同决定的。
2. VARMA(p,q) 模型的数学表达
这个模型的方程就是将VAR(p)和VMA(q)的方程简单地加在一起:
yt=c+VAR(p) 部分:系统的惯性A1yt−1+…+Apyt−p+VMA(q) 部分:冲击的记忆与当前冲击B1ϵt−1+…+Bqϵt−q+ϵt其中:
- 所有变量的定义(yt,c,Aj,Bj,ϵt)都与我们在VAR和VMA模型中学习到的一致。
- 阶数 (p, q): p 指的是自回归部分的滞后阶数(惯性持续多久),而 q 指的是移动平均部分的滞后阶数(对冲击的记忆持续多久)。
关于误差项 ϵt 的假设与前两种模型完全一致:均值为零、同期相关、跨期不相关。
3. 滞后算子形式
使用滞后算子 L,VARMA 模型可以表示为非常紧凑的形式:
yt(I−A1L−…−ApLp)ytyt=c+(A1L+…+ApLp)yt+(I+B1L+…+BqLq)ϵt=c+(I+B1L+…+BqLq)ϵt=(I−A1L−…−ApLp)−1[c+(I+B1L+…+BqLq)ϵt]这个最终的表达式是模型最深刻的刻画。它表明,当前的观测值 yt 可以理解为常数项和所有历史冲击序列,经过一个复杂的线性滤波器 (I−A1L−…−ApLp)−1(I+B1L+…+BqLq) 变换后的结果。
4. 模型的长期性质
-
长期均值向量 (μ):
对模型两边取期望,所有冲击项 ϵ 的期望为零,因此有:
μ=c+A1μ+…+Apμ
求解这个关于 μ 的方程,即可得到:
μVARMA(p,q)=(In−A1−⋯−Ap)−1c(3.33)
结论:VARMA 模型的长期均值只取决于截距项 c 和自回归系数矩阵 Aj,与移动平均部分 Bj 无关。这与 VAR 模型的结论一致。
-
长期协方差矩阵 (Σy):
计算 VARMA 模型的协方差矩阵 Σy=E[(yt−μ)(yt−μ)′] 在理论上非常复杂。一个标准且强大的技巧是将 VARMA(p, q) 模型等价地转换为一个 VAR(1) 模型(通过状态空间扩充,如公式 3.34, 3.35 所示)。
这个 VAR(1) 表示法的形式为:
Yt=C+AYt−1+Et
其中 Yt 是一个将 yt 及其滞后项、以及 ϵt 及其滞后项全部堆叠在一起构成的状态向量,其维度远大于 n。A 是一个由原 VARMA 模型所有系数矩阵 Aj 和 Bj 构成的大矩阵。
一旦转化为 VAR(1) 形式,其协方差矩阵 ΓY(0)=E[YtYt′] 就可以通过求解一个特殊的方程(李雅普诺夫方程)得到:
ΓY(0)=AΓY(0)A′+ΣE(3.36)
其中 ΣE 是转换后新扰动项 Et 的协方差矩阵。通过向量化算子 vec(⋅),这个方程可以解出:
vec(ΓY(0))=(I−A⊗A)−1vec(ΣE)(3.37)
最终,我们所需要的 n 个原始变量 yt 的协方差矩阵 Σy,就是这个巨大矩阵 ΓY(0) 的左上角的 n×n 子块:
ΣVARMA(p,q)=ΓY(0)[1:n,1:n](3.38)